Key Takeaways
- Serverless computing provides automatic scaling and less operational overhead, but it comes with cold start latency and the risk of vendor lock-in
- Container deployments offer more control, portability across environments, and consistent performance, but they require more manual infrastructure management
- Performance characteristics vary greatly: serverless is excellent with variable workloads, while containers are better for consistent, long-running processes
- Cost structures are fundamentally different – serverless uses a pay-per-execution model, while containers typically use resource allocation pricing
- SlickFinchf can assist companies in navigating the deployment decision process with expert cloud consultants who understand both models
The decision between serverless and container-based deployment can significantly affect your application’s performance, cost structure, and team workflow. This decision should not be taken lightly.
With the rise of cloud-native technologies, developers are now tasked with navigating a myriad of deployment options that can make or break an application. Both serverless and container-based deployments have come a long way, each boasting its own set of benefits for certain situations and its own set of drawbacks for others. Recognizing these distinctions is crucial to choosing the right strategy for your application from the start, and mitigating any problems later on. It informs everything from architectural choices to operational expenses.
Having worked on numerous cloud deployments at SlickFinch, we’ve seen the good, the bad, and the ugly. The right deployment model can make your development process faster and more cost-effective, but the wrong one can land you in a world of technical debt and operational nightmares. Let’s take a closer look at the key differences between serverless and container-based deployment to help you make the best choice for your next project.
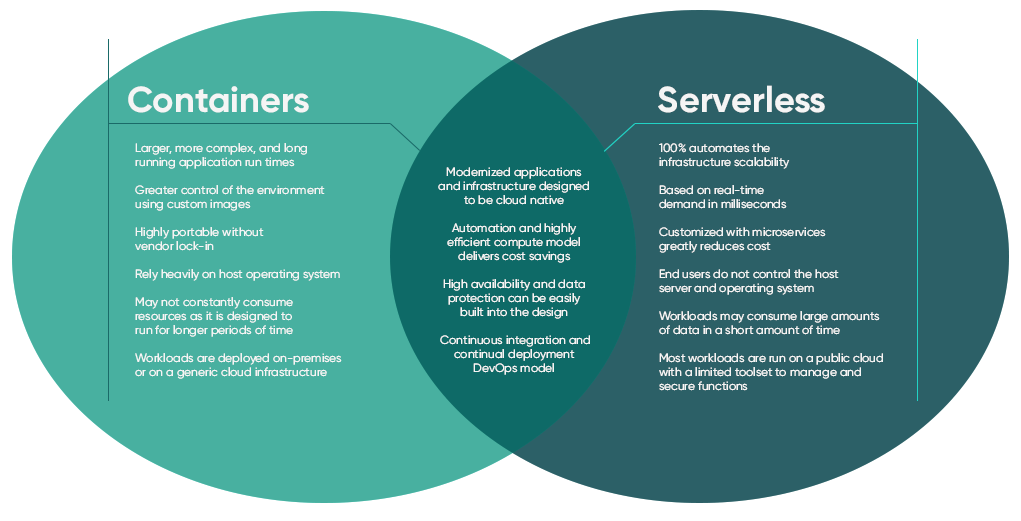
“Serverless vs. Containers: Which is …” from controlplane.com and used with no modifications.
Cloud Deployment Face-off: Serverless versus Containers
Serverless and container technologies are two very different ways to deploy modern applications. Both aim to make deployment easier and improve scalability, but they do so in different ways. The best choice ultimately depends on the specific needs of your application, the expertise of your team, and the constraints of your business.
The majority of companies are currently either assessing or employing one or both of these technologies, with Datadog stating that half of the companies that use containers are also adopting serverless functions. This mixed strategy is becoming more popular as teams realize that these technologies can supplement each other rather than compete. The trick is to know where each excels and where each fails.
Understanding Serverless and Container Deployments
Before we start comparing these two technologies, it’s important to understand what they are and how they work. Both serverless and container deployments are cloud-native options, but they are fundamentally different. They offer different levels of control for developers and operational simplicity.
These distinctions aren’t just about the technical aspects of implementation, they’re about different ways of thinking about cloud computing. Serverless is all about abstraction and managed services, while containers are a compromise between old-school servers and fully managed cloud resources.
Serverless Computing: No More Server Management
Serverless computing is a model where the cloud provider takes care of the server allocation and provisioning. All a developer has to do is upload their code, and the cloud provider takes care of everything else needed to run and scale the code. Even though it’s called serverless, servers are still involved—they’re just hidden from the developer.
Major providers offer core serverless computing services like AWS Lambda, Azure Functions, and Google Cloud Functions. These platforms take care of all server management tasks, such as maintenance, capacity provisioning, and automatic scaling based on demand. Developers can concentrate solely on writing code that responds to events, whether they’re HTTP requests, database changes, file uploads, or scheduled triggers.
The serverless method is a pay-as-you-go model where you only pay for the exact resources used during function execution, which is measured in milliseconds. When your code isn’t running, you don’t pay any compute costs. This is a big change from the traditional always-on server models.
- Event-driven execution model with automatic scaling
- No server management or capacity planning required
- Microsecond billing for precise cost alignment with usage
- Native integration with cloud provider services
- Stateless execution with defined memory and time limits
Container-Based Deployment: Packaged Applications with Portability
Containers package an application and all its dependencies into a standardized unit for software development and deployment. Unlike virtual machines that virtualize an entire operating system, containers virtualize at the application layer, sharing the host system’s OS kernel but running in isolated user spaces.
Thanks to Docker, container technology has become standardized and user-friendly. Meanwhile, orchestration platforms such as Kubernetes offer the infrastructure necessary to deploy, manage, and scale applications that have been containerized. This combination creates a robust ecosystem for deploying complex applications with consistent behavior, regardless of the environment.
Container-based application deployment allows developers to have significant control over the runtime environment while providing reasonable isolation and resource efficiency. Each container comes with everything required to run the application – the code, runtime, system tools, libraries, ensuring that the behavior is consistent regardless of the environment it is running in. This portability is a significant advantage, allowing for a smooth transition between development, testing, and production environments.
“Containers offer a best-of-both-worlds approach: they provide much of the environmental consistency and resource efficiency of virtual machines with the abstraction and process isolation that makes serverless attractive to developers.” – Kelsey Hightower, Google Cloud Principal Engineer
Performance Face-Off: Speed, Scale, and Reliability
Performance characteristics differ significantly between serverless and container-based deployments, with each model optimized for different workload patterns. These differences impact application responsiveness, scalability limits, and overall user experience in distinct ways that must be considered in your architecture decisions.
The performance differences between serverless and container-based application deployment are based on their core design principles. Serverless focuses on executing on demand and scaling automatically, while containers provide more predictable performance and more control over the runtime environment. Neither is better than the other in all situations – the best option depends on the specific characteristics and performance needs of your workload.
Serverless Cold Start Issues vs Container Warm-Up
One of the biggest performance hurdles in serverless computing is cold starts. If a function hasn’t been used recently, the cloud provider has to set up a new execution environment before your code can run. This adds latency that can be anywhere from a few hundred milliseconds to several seconds. The amount of time it takes for this initialization to occur can vary based on the provider, runtime, code size, and dependencies. This makes performance less predictable for functions that aren’t accessed frequently.
Unlike serverless, containers are already “warm” once they start, which means there are no initialization delays for future requests. The downside is that containers use resources even when they’re not being used, which means you’re paying for them whether you’re using them or not. Some serverless platforms offer “provisioned concurrency” options to keep environments warm and reduce cold starts, but this can end up costing as much as containers because you’re paying for capacity even when you’re not using it.
Under Pressure: How Each Handles Traffic Spikes
Serverless platforms are excellent at handling unpredictable traffic patterns and sudden spikes. They can automatically scale from zero to thousands of concurrent executions within seconds, without any configuration or intervention needed. This immediate elasticity makes serverless perfect for applications with highly variable workloads, unpredictable traffic, or seasonal usage patterns.
While container scaling is a potent tool, it usually needs more configuration and has a bit more latency. Orchestration platforms like Kubernetes keep an eye on resource usage and add or remove container instances based on set rules. While this process is efficient, it includes scheduling decisions, image pulling, and container initialization, which can take a few seconds or minutes to fully complete.
Serverless scaling models are great because they get rid of the need for capacity planning and over-provisioning, which can save you money if your workloads tend to burst. However, if you need more control over the scaling algorithm and infrastructure distribution, or if your applications have specific performance requirements or complex dependencies, containers are the way to go.
Long-Term Projects: The Strength of Containers
Most serverless platforms have execution time limits, usually between 15-30 minutes. This makes them unsuitable for long-term processes. When your workload involves a lot of data processing, operations that require a lot of computation, or continuous background processing, containers are a better runtime environment because they don’t have arbitrary timeout limits.
Containers can run as long as they need to, making them perfect for batch processing jobs, machine learning training, complex ETL workflows, or any task that may take an unknown amount of time to complete. Serverless platforms have ways to get around this like chaining functions or using step functions, but these methods can make things more complicated and add more places where things could go wrong compared to just using one containerized process.
Containers are also better for CPU-intensive tasks due to their predictable performance. Serverless platforms often throttle CPU performance in order to maintain fair resource sharing across the platform, and prioritize I/O-bound tasks over CPU-bound tasks.
Workflow and Development Experience
The daily experience of a developer can vary greatly depending on whether they are working with serverless or container-based development. These differences can affect everything from testing locally to deployment cycles, and they can significantly affect the productivity and satisfaction of a team.
Consider your team’s current skills and preferences when making a decision. Learning new deployment models can temporarily decrease productivity, so you should choose the technology that is most compatible with your team’s existing capabilities and that meets your application requirements.
Local Testing: The Benefits of Containers for Developers
Containers offer a significant benefit for local development and testing, providing a nearly identical experience between development and production environments. Developers can run the same container image locally that will eventually be deployed to production, eliminating the “it works on my machine” issue. Tools like Docker Compose make it easy to run multi-container applications locally, including dependencies like databases and message queues.
In contrast, serverless development typically depends more on cloud-based testing or local emulation tools that come close to – but don’t exactly replicate – the production environment. Although frameworks like the Serverless Framework, AWS SAM, and various emulators have improved the situation, they still don’t offer the same level of environmental consistency as containers. Testing serverless applications often involves deploying to a development stage in the cloud, which can slow down the feedback loop.
Comparing Support for Languages and Runtimes
When it comes to choosing a language or runtime, containers provide unparalleled flexibility. You can use almost any programming language, version, or framework that can run on Linux (and increasingly, Windows). This flexibility also applies to custom runtimes, proprietary software, and legacy applications with specific dependency requirements that may not be supported in serverless environments.
Serverless platforms tend to support a narrower range of languages and runtimes, although the main providers are continually broadening their offerings. For instance, AWS Lambda natively supports JavaScript, Python, Java, Go, .NET, and Ruby, with custom runtime options available for other languages. However, even with custom runtimes, you’re limited by the underlying execution environment and can’t change system-level components or install any binary dependencies you want.
| Feature | Containers | Serverless |
|---|---|---|
| Language & Runtime Support | Supports any language, runtime, or binary dependency that can run on the host OS. | Limited to provider-supported languages or custom runtimes within platform constraints. |
| Runtime Versions & Patching | Full control over runtime versions and patching. | Managed by the provider with automatic updates. |
| Dependencies & Software | Can include proprietary or licensed software. | Generally limited to open-source or pre-approved dependencies. |
Debugging Capabilities: How to Find Issues in Production
Container environments offer more familiar and comprehensive debugging options. They provide access to traditional tools like interactive shells, log files, profilers, and debuggers. When issues arise in production, developers can often execute diagnostic commands directly in the container. They can even attach debuggers to running processes in development environments, making it a viable option for container strategy.
Debugging serverless applications can be more difficult due to the short-lived nature of function instances and the limited ability to access the underlying execution environment. Debugging is usually heavily dependent on logs, metrics, and traces that are exported to monitoring systems, as opposed to directly interacting with the runtime. While cloud providers are offering more and more advanced tools for observing serverless applications, the process of debugging is quite different from traditional application development.
When it comes to debugging capabilities, there is a significant difference that can greatly affect how quickly incidents are responded to and how developers experience troubleshooting complex issues. Teams should think about setting up strong logging and monitoring practices, especially for serverless applications where direct access to the runtime is limited.
Cost Structures That Affect Your Profits
The cost of serverless versus container deployments isn’t just about the price tag. The two different cost models need different ways to optimize and can greatly change how much you spend on cloud services, depending on how your application is used.
It’s essential to understand these cost structures to accurately forecast costs and make informed architectural decisions. What seems cost-effective during development may be costly at scale, or vice versa, depending on your workload characteristics.
Pay-As-You-Go vs. Pay-For-Resources Pricing
Serverless computing brought the concept of true pay-as-you-go pricing to the cloud computing world, charging only for the exact resources used during function execution. Costs usually pile up based on three factors: the number of requests, execution duration (usually measured in 100ms increments), and allocated memory. This model can be very cost-effective for applications with intermittent traffic, as you pay nothing when your code isn’t running.
When it comes to container pricing, it uses a more conventional resource allocation model. This means you pay for the base infrastructure, which is usually Kubernetes nodes or a similar type of computing resource, whether you’re using the actual container or not. Although this method requires more detailed capacity planning to prevent over-provisioning, it does give you more predictable costs for steady workloads. It can also be more cost-effective for applications with high and consistent utilization.
The point at which these models become equivalent in cost varies depending on the workload. However, as a rule of thumb, serverless tends to be more expensive than containers as utilization goes up. For applications that are running all day, every day, with traffic that can be predicted, containers are usually the more cost-effective option. On the other hand, serverless is typically cheaper for workloads that are either infrequent or highly variable.
|
Aspect |
Serverless |
Containers |
|---|---|---|
|
Idle costs |
Zero |
Full infrastructure costs |
|
Utilization efficiency |
Perfect (pay only for what you use) |
Depends on capacity planning and autoscaling configuration |
|
Cost predictability |
Variable based on execution |
More predictable for steady workloads |
|
Price optimization |
Function duration, memory tuning |
Resource allocation, instance selection |
|
Traffic pattern suitability |
Intermittent, variable |
Consistent, predictable |
Hidden Costs in Both Models
Beyond the obvious pricing dimensions, both deployment models involve less visible costs that should factor into your decision. For serverless, these include data transfer charges, API Gateway costs (for HTTP functions), potential cold start mitigations like provisioned concurrency, and storage costs for function packages. Additionally, functions with inefficient code can incur significantly higher costs due to extended execution times or excessive memory allocation.
Deploying containers comes with its own set of hidden costs, including the costs of controlling Kubernetes clusters, load balancer fees, persistent volume storage, and the operational overhead of managing container orchestration. Companies also need to take into account the human resource costs of building and maintaining container expertise, which usually requires more specialized knowledge than serverless deployments.
Differences in Attack Surface
- Serverless applications have a smaller attack surface because the cloud provider is responsible for infrastructure security
- Container security involves protecting the container runtime, orchestrator, and application layers
- Containers can have vulnerable dependencies or outdated base images if they are not regularly maintained
- Serverless functions can be vulnerable to event-injection attacks via their triggers
- Container privilege escalation can be a problem if the configuration allows for too many permissions
The security boundaries in serverless and container deployments are fundamentally different in terms of both responsibility and implementation. Serverless architectures shift much of the security burden to the cloud provider, who is responsible for the security of the execution environment, operating system, and runtime. This significantly reduces your attack surface, but it also limits your visibility into the security measures for the underlying infrastructure.
Containers necessitate more thorough security measures because you must secure the container images, runtime environment, and orchestration layer. Each container could introduce vulnerabilities due to out-of-date base images, insecure configurations, or excessive permissions. The container ecosystem offers strong security tools such as vulnerability scanners, admission controllers, and runtime security monitoring, but using these effectively requires specialized security knowledge.
The ways in which networks can be attacked also vary between the two models. Serverless functions usually have short-lived network identities and more limited communication patterns, while containers have network identities that last longer and could be more vulnerable to lateral movement attacks if they are compromised. Companies will need to change their security monitoring and incident response methods to take these differences into account.
Meeting Compliance and Regulatory Standards
Depending on the industry, regulatory compliance requirements can greatly impact the choice of deployment model. While serverless architectures can ease compliance in some respects by shifting responsibility to the cloud provider, they can also make it more complex due to the shared responsibility model and possible lack of transparency. Industries with rigid data sovereignty requirements or specialized compliance needs like healthcare (HIPAA), finance (PCI-DSS), or government (FedRAMP) must thoroughly assess whether serverless offerings satisfy their regulatory duties or if containers offer the needed control.
Mixed Methods: Utilizing the Strengths of Both
Several businesses are realizing that the serverless and containers debate isn’t a matter of choosing one over the other. Instead, it’s a chance to use the advantages of each method in various parts of their application architecture. These mixed methods recognize that contemporary applications have a variety of components with different operational needs, performance features, and development patterns. Teams can maximize both developer productivity and operational effectiveness by applying the appropriate deployment model to each component.
Using FaaS Within Containers
Open-source projects are now available that allow you to run function-as-a-service platforms within your own container infrastructure. Technologies like Knative, OpenFaaS, and Kubeless have brought serverless programming models and auto-scaling capabilities to Kubernetes environments. This means that teams can continue to maintain container-based infrastructure while also providing developers with a serverless experience. This approach provides greater control over the runtime environment and avoids vendor lock-in. At the same time, it still captures many of the benefits of serverless, such as scale-to-zero and event-driven architectures. Organizations that already have expertise in containers or that have made significant investments in Kubernetes often find that this hybrid model offers the perfect balance between operational control and developer productivity.
The Middle Ground: Serverless Containers
Cloud providers have noticed the need for container-based deployment with serverless operational characteristics. This has resulted in services like AWS Fargate, Azure Container Instances, and Google Cloud Run. These “serverless container” platforms manage infrastructure provisioning, scaling, and maintenance while still letting you deploy standard container images. This method allows developers to use familiar container tooling and workflows while getting rid of many operational burdens related to container orchestration. For organizations that value container portability but want to reduce infrastructure management overhead, these services offer an attractive middle ground that combines the best aspects of both models.
How to Choose: A Practical Approach
Deciding whether to go serverless, use containers, or a mix of both is not an easy decision. You have to consider several factors such as the nature of your application, the skills of your team, the needs of your business, and your operational limitations. Instead of thinking of this as a black and white decision, think of it as a range of options with different pros and cons for different parts of your application’s architecture.
When it comes to adopting cloud strategies, the most effective methods usually involve assessing each application or service on its own, taking into account its unique needs and limitations. Some components may thrive with the flexibility and ease of operation that serverless offers, while others may need the reliability and control that containers offer. The main point is to make these choices intentionally based on specific criteria, rather than resorting to a blanket approach.
Evaluating Your Team’s Abilities and Tools
The existing abilities and experience of your team should play a major role in determining your deployment strategy. Serverless adoption generally requires less operational expertise but a deeper understanding of cloud provider services and event-driven architecture patterns. Expertise in containers, especially with orchestration platforms such as Kubernetes, represents a significant commitment to specialized knowledge but offers more consistency across various environments. When assessing which technology best aligns with your human resources strategy, consider your current team makeup, training resources, and recruitment capabilities. Organizations with robust infrastructure teams may be able to use that strength with containers, while those focusing on application development may find serverless approaches that reduce operational overhead beneficial.
Understanding Your Application
Your application’s unique characteristics should inform your choice of deployment model. Serverless architectures are often a good fit for applications with unpredictable or highly variable traffic, distinct event triggers, and relatively independent components. On the other hand, applications with steady traffic, long-running processes, specific runtime requirements, or complex dependencies may be better off in containers. For more insights, explore the comparison between microservices and monolithic applications.
Take a close look at your application’s resource needs, state management requirements, execution patterns, and performance constraints, and weigh them against what each model can and can’t do. Remember to do this analysis at the component level, as different parts of your application may have different needs that call for different deployment strategies.
Preparing for Future Expansion and Development
Your deployment strategy should be able to meet both immediate needs and long-term growth. Think about how your application might expand in terms of traffic flow, geographical distribution, team size, and architectural intricacy. Serverless approaches often provide excellent initial developer speed and cost effectiveness for new projects but may present issues with vendor lock-in as applications develop. Container-based deployments usually require more initial investment but provide more flexibility for changing needs and multi-cloud strategies. The most future-proof method often involves building basic cloud-native design principles—like service separation, API-first design, and infrastructure as code—regardless of your specific deployment model.
When deciding between serverless and container-based application deployment, here are a few tips to keep in mind:
- Focus on your business needs and the nature of your application, rather than starting with a preferred technology.
- For key components, consider creating proof-of-concept versions using both serverless and container-based methods.
- Don’t just look at the costs of cloud resources. Also consider the operational complexity and total cost of ownership.
- Think about the learning curve for your team and the organizational changes that might be needed.
- From the outset, plan for your observability and debugging needs.
Keep in mind that cloud-native architectures are evolving rapidly. The lines between serverless and container deployments are becoming increasingly blurred. Services like AWS App Runner, Google Cloud Run, and Azure Container Apps are points of convergence that combine container packaging with serverless operational models. This suggests that focusing on cloud-native principles and practices might be more important in the long run than choosing either serverless or containers exclusively.
Many organizations find that the best approach is to use both models in a strategic manner—serverless for highly elastic workloads and rapid development, and containers for complex applications that require more control. This practical strategy acknowledges that different workloads have different needs, and lets you take advantage of the strengths of each model where it makes sense.
Common Questions
When companies are deciding between serverless and container deployments, there are often a few questions that come up again and again. Here are the answers to some of those questions, which should help you make a more informed decision about your architecture.
Is it possible for serverless applications to interact with containerized applications?
Indeed, serverless functions are capable of interacting with containerized applications using standard network protocols and APIs. The way they integrate is determined by your unique architecture and network setup.
“For hybrid architectures, API gateways often serve as the communication fabric connecting serverless functions with containerized services. This approach provides a clean interface boundary while enabling centralized request routing, authentication, and monitoring.” – Adrian Cockcroft, former VP of Cloud Architecture Strategy at AWS
Most cloud providers offer virtual private cloud (VPC) integration for serverless functions, allowing them to access private container endpoints within the same network. For cross-cloud or hybrid scenarios, you can expose containerized services through API gateways, load balancers, or service meshes that serverless functions can then call via HTTP/HTTPS.
Event-driven patterns also work well for hybrid architectures, with message queues or event buses serving as intermediaries between serverless and container components. This approach provides decoupling and can help manage the different scaling characteristics of each deployment model.
When it comes to creating hybrid frameworks, you need to focus on authentication, error management, and retry logic. If you don’t manage these integration points well, they can become points of failure.
What are the differences in monitoring and observability between serverless and container-based deployments?
Monitoring serverless applications needs a different method compared to the usual container monitoring because they are transient and there is limited access to the underlying infrastructure. Observability in serverless usually focuses on metrics per invocation, cold start detection, and tracing across multiple function executions, rather than continuous process or host-level monitoring.
Container observability has the advantage of having established tools that can monitor at multiple levels: the health of the container, application metrics, the status of the orchestration platform, and the underlying infrastructure. This multi-layered visibility often provides more comprehensive debugging information, but it requires more complex monitoring configuration and maintenance.
Both approaches can take advantage of distributed tracing to comprehend request flows across components, but serverless environments usually require more thoughtful instrumentation due to the stateless execution model and the possibility of cold starts. Cloud providers are increasingly offering specialized observability services for serverless deployments that tackle these specific challenges, while container ecosystems usually use existing monitoring stacks with extensions specific to Kubernetes.
Can you switch from serverless to containers or the other way around?
Indeed, it is possible to transition between serverless and container deployments, but the difficulty of the task depends on the architecture of your application and the extent to which it is integrated with platform-specific services. Applications that have been designed to separate business logic from infrastructure issues are easier to transition in either direction. The most successful transitions usually involve refactoring applications into smaller, more focused services with well-defined interfaces before changing deployment models. This method allows for gradual transition rather than risky all-at-once changes, and it provides opportunities to reconsider service boundaries and communication patterns during the process.
Which deployment model provides superior disaster recovery solutions?
Both models offer robust disaster recovery strategies, but they do so in different ways and with different trade-offs. Serverless architectures take advantage of built-in multi-AZ (Availability Zone) deployment in most cloud providers, with automatic failover handling and no infrastructure to recover. Their stateless nature and declarative deployment models make regional failover relatively straightforward, as you can redeploy function definitions to alternate regions when needed.
While container-based architectures do require more explicit planning and testing, they provide more control over disaster recovery processes. High resilience can be achieved with multi-region Kubernetes clusters with appropriate storage replication, but they require significant operational expertise to implement correctly. The container approach provides more visibility into and control over the recovery process, while serverless provides simplicity at the cost of some transparency.
What are the differences between serverless and container deployments in CI/CD pipelines?
When it comes to serverless CI/CD pipelines, the main focus is on function packaging, configuration management, and direct deployment to the cloud provider’s function service. Although these pipelines are usually simpler, they are more specific to the provider. They often use frameworks such as the Serverless Framework, AWS SAM, or deployment tools specific to the provider. Testing serverless applications in CI/CD pipelines can be difficult, often requiring test environments deployed in the cloud or specialized local emulators.
Container CI/CD pipelines focus on the creation, examination, and distribution of container images, then updating deployment configurations in the orchestration platform. These pipelines are typically more uniform across providers but involve additional steps, such as vulnerability scanning, image optimization, and registry management. The container model gains from increased environment consistency between development, testing, and production, potentially allowing for more thorough automated testing within the pipeline.
No matter what deployment model you use, modern CI/CD best practices are relevant to both methodologies: infrastructure as code, automated testing, incremental deployments, and rollback capabilities are still crucial for dependable delivery. Organizations with existing CI/CD expertise will discover that the basic principles carry over between models, even though the specific tools and implementation details will vary.
Serverless application deployment offers several advantages over traditional container-based deployment. For one, serverless applications can be scaled up or down automatically, without the need for manual intervention. This can be a major advantage for businesses that experience sudden spikes in traffic or demand. Additionally, serverless applications can be deployed much more quickly than container-based applications, which can save businesses a significant amount of time and resources.
However, there are also some disadvantages to serverless application deployment. For example, serverless applications can be more difficult to debug and test than container-based applications. This is because serverless applications are typically run in a stateless environment, which can make it difficult to reproduce bugs or errors. Additionally, serverless applications can be more expensive to run than container-based applications, especially for businesses that have a high volume of traffic or demand.
On the other hand, container-based application deployment also offers several advantages. For example, container-based applications can be more flexible and customizable than serverless applications. This is because container-based applications are typically run in a stateful environment, which allows developers to have more control over the application’s behavior and performance. Additionally, container-based applications can be more cost-effective than serverless applications, especially for businesses that have a low volume of traffic or demand.
There are also some disadvantages to container-based application deployment. For example, container-based applications can be more difficult to scale up or down than serverless applications. This is because container-based applications typically require manual intervention to scale, which can be time-consuming and resource-intensive. Additionally, container-based applications can be slower to deploy than serverless applications, which can delay the delivery of new features or updates.
If you need help choosing the best deployment model for your specific needs and want to implement effective cloud strategies, SlickFinch offers professional consulting services that can guide you through these complex architectural choices.