Key Takeaways
-
Seldon.io simplifies machine learning model deployment on Kubernetes, making it accessible even for beginners.
-
Kubernetes provides scalability, flexibility, and strong community support, ideal for ML model deployment.
-
Seldon Core integrates seamlessly with Kubernetes, offering features like model versioning, monitoring, and scaling.
-
Setting up Seldon Core involves straightforward steps: installing Kubernetes, Helm, and Seldon Core itself.
-
Deploying models with Seldon Core requires creating a SeldonDeployment manifest and using kubectl for deployment.
How Seldon.io Simplifies ML Model Deployment on Kubernetes
What is Seldon.io?
Seldon.io is an open-source platform designed to make deploying machine learning models straightforward and efficient. It wraps your machine learning models and exposes them as services that can be easily managed and scaled. Seldon.io leverages Kubernetes, a powerful container orchestration platform, to ensure your models run smoothly in production environments.
The Basics of Kubernetes
Before diving into how Seldon.io works, let's quickly go over Kubernetes. Kubernetes, often abbreviated as K8s, is an open-source platform designed to automate deploying, scaling, and operating application containers. It groups containers that make up an application into logical units for easy management and discovery.
Think of Kubernetes as a master conductor for your container orchestra, ensuring each container performs its role perfectly and scales according to the needs of your application.
The Challenges of Traditional ML Model Deployment
Deploying machine learning models traditionally can be a daunting task. It involves numerous steps, from setting up infrastructure to ensuring that the model scales efficiently. Besides that, managing different versions of the model and rolling back to previous versions if something goes wrong can be a headache. For a comprehensive approach to AI model lifecycle management, leveraging tools like Kubeflow on Kubernetes can streamline the process.
Most importantly, traditional methods often lack robust monitoring and alerting mechanisms, making it difficult to track model performance and take corrective actions promptly.
"Quickstart — seldon-core documentation" from docs.seldon.io and used with no modifications.
{kind=link}
Why Choose Kubernetes for ML Deployment?
Scalability and Flexibility
Kubernetes shines when it comes to scalability and flexibility. It allows you to scale your machine learning models horizontally by adding more replicas. This ensures that your application can handle increased loads without a hitch.
Moreover, Kubernetes offers the flexibility to run your models on any infrastructure, whether it's on-premises, in the cloud, or a hybrid setup.
Containerization Benefits
By containerizing your machine learning models, you can ensure consistency across different environments. Containers encapsulate all the dependencies your model needs, making it easier to deploy and run anywhere. This eliminates the "it works on my machine" problem, ensuring that your model runs seamlessly in production.
Community Support and Resources
One of the significant advantages of using Kubernetes is its robust community support. With a large and active community, you'll find plenty of resources, tutorials, and tools to help you get started and troubleshoot any issues you encounter.
Additionally, Kubernetes has a rich ecosystem of tools and extensions, making it easier to integrate with other platforms and services you might be using.
Introduction to Seldon Core
Overview and Features
Seldon Core is an open-source platform that simplifies deploying, scaling, and managing machine learning models on Kubernetes. It offers a range of features designed to make your life easier, including:
-
Model versioning and rollback capabilities
-
Real-time monitoring and alerting
-
Horizontal scaling of model deployments
-
Support for multiple machine learning frameworks and languages
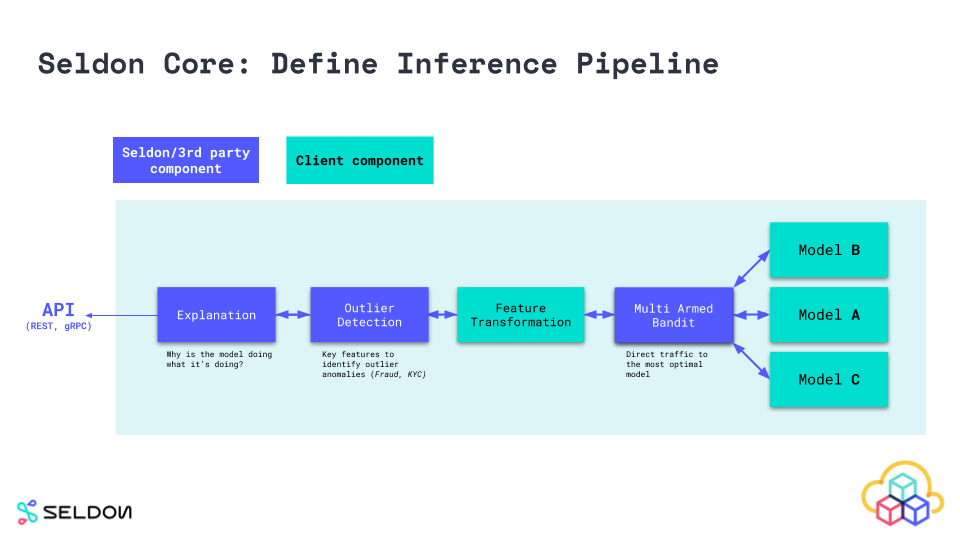
Seldon Core's Architecture
Seldon Core's architecture is built on top of Kubernetes, leveraging its powerful orchestration capabilities. At its core, Seldon uses Custom Resource Definitions (CRDs) to define and manage machine learning deployments. This allows you to treat your models as first-class citizens in your Kubernetes cluster.
The architecture consists of several key components, including the Seldon Engine, which orchestrates the deployment and scaling of your models, and various integrations for monitoring and alerting.
How Seldon Core Integrates with Kubernetes
Seldon Core integrates seamlessly with Kubernetes, allowing you to deploy and manage your machine learning models using familiar Kubernetes tools and workflows. You can define your model deployments using YAML manifests and deploy them using kubectl, the Kubernetes command-line tool.
This integration ensures that you can leverage all the powerful features of Kubernetes, such as horizontal scaling, rolling updates, and robust monitoring, to manage your machine learning models effectively.
Setting Up Your Environment
Installing and Configuring Kubernetes
Before you can start deploying models with Seldon Core, you need to set up a Kubernetes cluster. There are several ways to do this, depending on your requirements and the infrastructure you're using.
If you're just getting started, you can use a local Kubernetes cluster like Minikube or Podman. These tools allow you to run Kubernetes on your local machine, making it easy to experiment and learn.
For production environments, you'll likely want to use a managed Kubernetes service like Google Kubernetes Engine (GKE), Amazon Elastic Kubernetes Service (EKS), or Azure Kubernetes Service (AKS). These services take care of the heavy lifting, providing you with a ready-to-use Kubernetes cluster.
Installing Seldon Core Using Helm
Once your Kubernetes cluster is up and running, the next step is to install Seldon Core. The easiest way to do this is using Helm, a package manager for Kubernetes.
First, you'll need to install Helm on your local machine. You can do this by following the instructions on the Helm website. Once Helm is installed, you can add the Seldon Core Helm repository and install Seldon Core with the following commands:
helm repo add seldonio https://storage.googleapis.com/seldon-charts
helm repo update
helm install seldon-core seldonio/seldon-core-operator --namespace seldon-system --create-namespace
These commands add the Seldon Core Helm repository, update your local Helm repository cache, and install the Seldon Core operator in a new namespace called seldon-system.
Deploying Machine Learning Models with Seldon Core
Deploying machine learning models with Seldon Core on Kubernetes is a streamlined process. By following a few key steps, you can have your model up and running in no time. Let’s walk through the essential steps to get your model deployed.
Preparing Your Model for Deployment
Before deploying your model, you need to ensure it is properly prepared. This involves containerizing your model, which means packaging it along with all its dependencies into a Docker container. This step ensures consistency across different environments, making it easier to deploy your model on Kubernetes.
You can use various tools to containerize your model, such as Docker. Here’s a simple Dockerfile example for a Python-based machine learning model:
FROM python:3.8-slim
COPY . /app
RUN pip install -r requirements.txt
CMD ["python", "your_model_script.py"]
In this Dockerfile, we start with a base Python image, set the working directory, copy the model files, install the necessary dependencies, and specify the command to run the model script.
Creating a SeldonDeployment Manifest
Once your model is containerized, the next step is to create a SeldonDeployment manifest. This manifest is a YAML file that defines how your model should be deployed on Kubernetes. It includes details such as the model image, replicas, and resource requirements.
Here’s an example of a SeldonDeployment manifest:
apiVersion: machinelearning.seldon.io/v1
kind: SeldonDeployment
metadata:
name: my-model-deployment
predictors:
- name: default
graph:
name: my-model
implementation: SKLEARN_SERVER
modelUri: gs://my-bucket/my-model
componentSpecs:
- spec:
containers:
- name: my-model
image: my-docker-repo/my-model:latest
In this manifest, we define a SeldonDeployment with one predictor. The predictor uses the SKLEARN_SERVER implementation and specifies the model URI and Docker image. You can customize this manifest based on your specific requirements.
Deploying the Model with kubectl
With your SeldonDeployment manifest ready, you can deploy your model using kubectl, the Kubernetes command-line tool. Simply apply the manifest to your Kubernetes cluster with the following command:
kubectl apply -f my-seldon-deployment.yaml
This command tells Kubernetes to create the resources defined in your manifest. Once the deployment is complete, you can verify that your model is running by checking the status of the SeldonDeployment:
kubectl get seldondeployment my-model-deployment
This command will show you the status of your SeldonDeployment, including the number of replicas and their readiness status.
Versioning and Rollback Strategies
Managing different versions of your machine learning models is crucial for maintaining performance and reliability. Seldon Core provides robust versioning and rollback capabilities to help you manage this effectively.
Managing Model Versions
To manage different versions of your model, you can use the version field in the SeldonDeployment manifest. By specifying different versions, you can deploy multiple versions of the same model and switch between them as needed.
For example, you can update your SeldonDeployment manifest to include a new version of your model:
- name: default
graph:
name: my-model
implementation: SKLEARN_SERVER
modelUri: gs://my-bucket/my-model-v2
- spec:
containers:
- name: my-model
image: my-docker-repo/my-model:v2
Rolling Back to Previous Versions
If you encounter issues with a new version of your model, Seldon Core makes it easy to roll back to a previous version. Simply update the SeldonDeployment manifest to point to the previous model version and apply the changes using kubectl.
This rollback capability ensures that you can quickly revert to a stable version of your model if something goes wrong, minimizing downtime and maintaining reliability.
A/B Testing and Canary Deployments
Seldon Core also supports advanced deployment strategies like A/B testing and canary deployments. These strategies allow you to test new versions of your model with a subset of users before rolling them out to your entire user base.
For A/B testing, you can deploy multiple versions of your model and route a percentage of traffic to each version. This helps you compare the performance of different versions and make data-driven decisions. To understand more about deploying models, check out deploying NLP models with MLOps tools.
Canary deployments, on the other hand, involve gradually rolling out a new version of your model to a small subset of users. If the new version performs well, you can gradually increase the traffic until it fully replaces the old version.
Here’s an example of how you can configure a canary deployment in your SeldonDeployment manifest:
predictors:
- name: [canary](https://slickfinch.com/blog/kubernetes-native-tools-ai-workflow-orchestration/)
replicas: 1
Traffic: 10
graph:
name: my-model-canary
containers:
- name: my-model-canary
image: my-docker-repo/my-model:v2
In this manifest, we define a canary predictor that receives 10% of the traffic, allowing us to test the new version of the model with a small subset of users.
For effective machine learning model deployment, leveraging tools like SKLEARN_SERVER can be essential.
For those looking to optimize their AI workloads, you might consider setting your modelUri to gs://my-bucket/my-model-v2
For more detailed information on Seldon Core, you can refer to the Seldon Core Documentation.
Monitoring and Scaling Your Models
Monitoring and scaling your machine learning models are essential for maintaining performance and reliability. Seldon Core provides robust tools and integrations to help you monitor and scale your models effectively.
Real-Time Monitoring with Grafana
Grafana is a powerful open-source platform for monitoring and observability. It integrates seamlessly with Seldon Core, allowing you to monitor your model’s performance in real-time.
You can set up Grafana to visualize metrics such as request latency, error rates, and resource usage. This helps you identify performance bottlenecks and take corrective actions promptly. For a more comprehensive understanding, check out this in-depth guide to Prometheus.
Horizontal Scaling Using Seldon Core
As the demand for your machine learning models increases, you may need to scale your deployments horizontally to handle higher loads. Seldon Core simplifies the scaling process, allowing you to add or remove replicas of your deployments dynamically.
You can configure horizontal scaling in your SeldonDeployment manifest by specifying the number of replicas. For example, to scale your deployment to three replicas, you can update the manifest as follows:
replicas: 3
graph:
modelUri: gs://my-bucket/my-model
componentSpecs:
- name: my-model
image: my-docker-repo/my-model:latest
Setting Up Alerts and Performance Metrics
To ensure your models are performing optimally, it’s essential to set up alerts and performance metrics. Seldon Core integrates with Prometheus, an open-source monitoring and alerting toolkit, to help you achieve this.
You can configure Prometheus to collect metrics from your Seldon Core deployments and set up alerts for specific conditions, such as high error rates or increased latency. For more details, check out this in-depth guide to Prometheus. This ensures that you are promptly notified of any issues and can take corrective actions.
Using Argo Workflows for Orchestration
Argo Workflows is a powerful open-source container-native workflow engine for orchestrating parallel jobs on Kubernetes. It's particularly useful for automating the deployment and update process of machine learning models. By integrating Argo Workflows with Seldon Core, you can create complex workflows that automate the entire lifecycle of your ML models, from training to deployment.
To get started, you'll need to install Argo Workflows on your Kubernetes cluster. You can do this using Helm:
helm repo add argo https://argoproj.github.io/argo-helm
helm install argo argo/argo-workflows --namespace argo --create-namespace
Once installed, you can define your workflows using YAML files. These workflows can include steps for training your model, containerizing it, and deploying it using Seldon Core. This level of automation ensures consistency and reduces the risk of human error.
Automating Deployments and Updates
Automating the deployment and update process is crucial for maintaining the efficiency and reliability of your machine learning models. With tools like Argo Workflows and CI/CD pipelines, you can automate the entire process, from code commit to model deployment.
Start by setting up a CI/CD pipeline using tools like Jenkins, GitLab CI, or GitHub Actions. These tools can be configured to trigger workflows whenever changes are made to your code repository. For example, you can set up a pipeline that builds a new Docker image of your model, pushes it to a container registry, and updates the SeldonDeployment manifest to deploy the new version.
Here's a simplified example of a GitHub Actions workflow for automating model deployment:
On: push
build:
runs-on: ubuntu-latest
steps:
- name: Checkout code
run: docker build -t my-docker-repo/my-model:${{ github.sha }} .
- name: Push Docker image
run: docker push my-docker-repo/my-model:${{ github.sha }}
- name: Update SeldonDeployment
Run: kubectl set image seldondeployment my-model-deployment my-model=my-docker-repo/my-model:${{ github.sha }}.
This workflow builds a new Docker image whenever changes are pushed to the repository, pushes the image to a Docker registry, and updates the SeldonDeployment to deploy the new version.
Security and Governance
Ensuring the security and governance of your machine learning models is critical, especially when dealing with sensitive data and complex models. Seldon Core provides several features to help you secure your models and comply with regulatory requirements. For best practices, you can refer to this guide on Kubernetes secrets management.
Ensuring Model Security
Securing your machine learning models involves protecting them from unauthorized access and ensuring the integrity of the model files. Seldon Core supports various authentication and authorization mechanisms to control access to your models.
You can use Kubernetes secrets to store sensitive information, such as API keys and passwords, securely. Additionally, Seldon Core integrates with Istio, a service mesh that provides robust security features, including mutual TLS, traffic encryption, and fine-grained access control.
Access Control and Permissions
Managing access control and permissions is crucial for maintaining the security of your machine learning models. Kubernetes provides role-based access control (RBAC) to manage permissions for different users and services.
With RBAC, you can define roles and assign them to users or service accounts, specifying the actions they are allowed to perform. For example, you can create a role that grants read-only access to model logs and metrics, ensuring that only authorized users can view this information.
Compliance and Regulatory Considerations
Compliance with regulatory requirements is essential for many industries, especially those dealing with sensitive data. Seldon Core helps you meet these requirements by providing robust auditing and logging capabilities. For more on integrating AI with existing infrastructure, check out tips and best practices for small businesses.
By integrating Seldon Core with tools like Elasticsearch and Kibana, you can collect and analyze logs from your model deployments, ensuring that you have a complete audit trail. This helps you demonstrate compliance with regulations such as GDPR, HIPAA, and SOC 2.
Future Trends and Improvements
The field of MLOps is rapidly evolving, with new technologies and best practices emerging regularly. Staying informed about these trends can help you improve your machine learning deployment processes and stay ahead of the competition.
-
Emerging Technologies in MLOps
-
Upcoming Features in Seldon Core
-
Community and Industry Insights
Emerging Technologies in MLOps
Several emerging technologies are shaping the future of MLOps. These include advanced model monitoring and explainability tools, automated feature engineering, and improved data versioning solutions. Keeping an eye on these developments can help you enhance your MLOps practices and deploy more robust and reliable models.
Upcoming Features in Seldon Core
Seldon Core is continually evolving, with new features and improvements being added regularly. Some upcoming features to look forward to include enhanced support for model explainability, improved integration with other MLOps tools, and more robust security features. Staying updated with these developments can help you leverage the latest capabilities of Seldon Core.
Community and Industry Insights
The MLOps community is a valuable resource for staying informed about the latest trends and best practices. Participating in community forums, attending conferences, and following industry leaders can provide valuable insights and help you stay ahead of the curve.
Frequently Asked Questions
What is the difference between Seldon Core and traditional ML Model deployment?
Seldon Core simplifies the deployment process by leveraging Kubernetes, offering features like model versioning, real-time monitoring, and horizontal scaling. Traditional deployment methods often lack these capabilities, making them less efficient and harder to manage.
Is Kubernetes necessary for using Seldon Core?
Yes, Kubernetes is a fundamental part of Seldon Core's architecture. It provides the underlying infrastructure for deploying, scaling, and managing your machine learning models. Without Kubernetes, you wouldn't be able to leverage the full capabilities of Seldon Core.
How does Seldon Core ensure the security of my models?
Seldon Core integrates with various security tools and frameworks, such as Istio and Kubernetes RBAC, to ensure the security of your models. It supports mutual TLS, traffic encryption, and fine-grained access control, helping you protect your models from unauthorized access and ensuring compliance with regulatory requirements.