Key Takeaways
-
Kubernetes logs are essential for troubleshooting and understanding application behavior.
-
Common log challenges include ephemeral resources, log volume, and performance impacts.
-
The EFK stack (Elasticsearch, Fluentd, Kibana) is a powerful solution for centralized log management.
-
Kibana offers robust features for analyzing, visualizing, and querying log data.
-
Effective log management can significantly improve operational success and reduce downtime.
Mastering Kubernetes Logs for Effective Troubleshooting with Kibana
Kubernetes has revolutionized the way we deploy and manage applications. However, with its distributed nature, troubleshooting can become a complex task. That's where Kubernetes logs come in. They provide critical insights into the behavior and performance of your applications.
Why Kubernetes Logs Matter
Logs are the lifeblood of any troubleshooting process. They offer a detailed account of what's happening inside your Kubernetes cluster. From application errors to resource allocation issues, logs can help you pinpoint the root cause of problems quickly.
"Logs are like the black box of your Kubernetes cluster. They record everything that happens, making them invaluable for troubleshooting."
Common Kubernetes Log Challenges
While logs are incredibly useful, they come with their own set of challenges. Understanding these challenges is the first step towards effective log management.
Ephemeral Resources and Log Persistence Issues
In Kubernetes, pods are ephemeral. They can be created and destroyed frequently, which poses a challenge for log persistence. If a pod crashes or is deleted, the logs generated by that pod can be lost.
To mitigate this, you need a centralized logging solution that can aggregate logs from all your pods and store them persistently. This ensures that you have access to logs even after the pods that generated them are gone.
-
Use persistent storage for log data.
-
Implement a centralized logging solution like the EFK stack.
-
Regularly back up your logs to prevent data loss.
Volume and Complexity of Log Data
Kubernetes applications can generate a massive amount of log data. Managing this volume of data can be overwhelming. Additionally, the logs can be complex, containing information from multiple layers and services.
To handle this, you need a robust log management system that can efficiently process, store, and analyze large volumes of log data. This is where the EFK stack comes into play.
Performance Impact of Traditional Logging Methods
Traditional logging methods can introduce performance overhead, especially in a high-traffic Kubernetes environment. Writing logs to disk can slow down your applications and consume valuable resources.
By leveraging a centralized logging system like the EFK stack, you can offload the logging process from your application nodes, thereby minimizing performance impact.
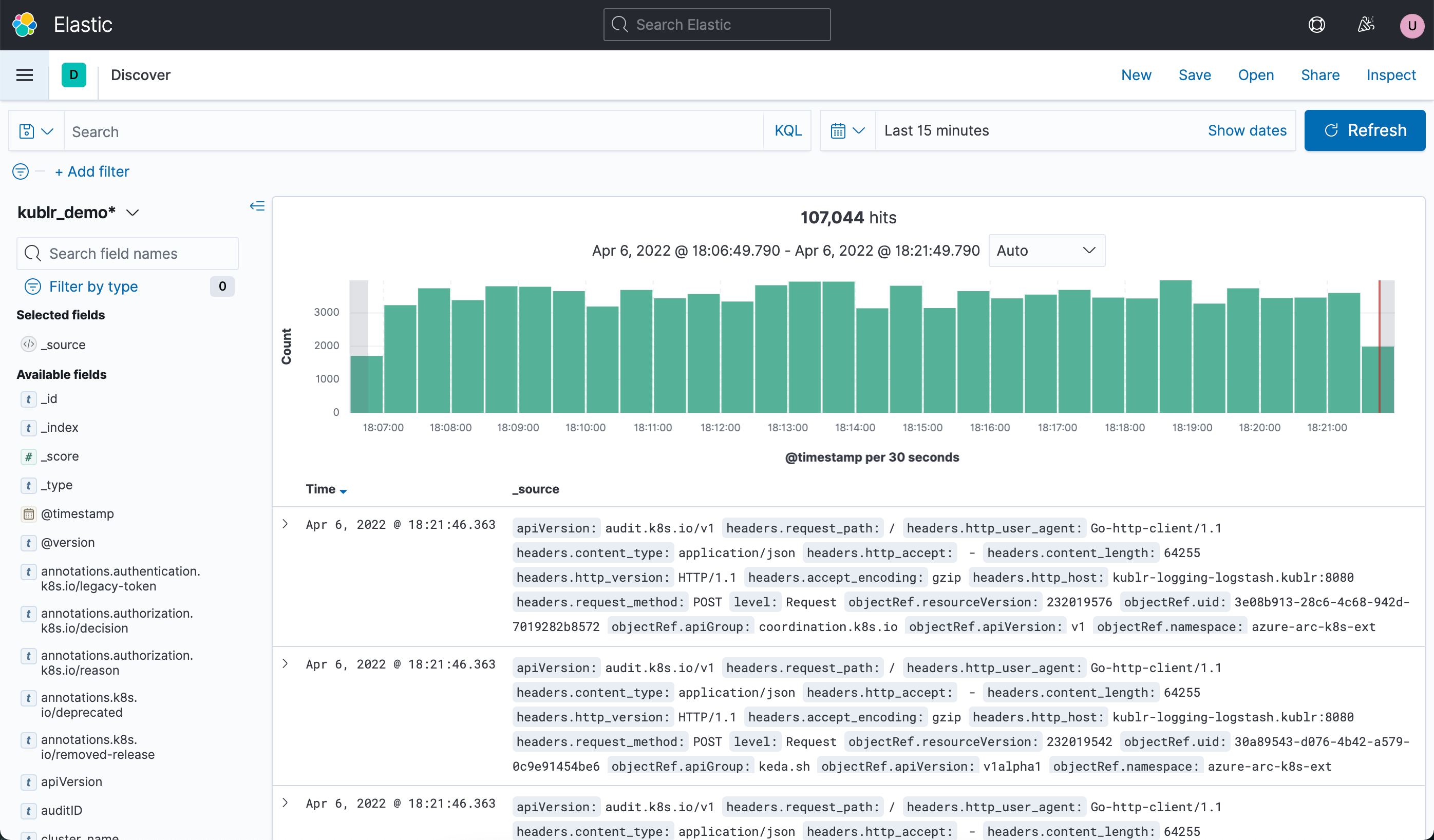
"Working with logs in Kibana :: Kublr ..." from docs.kublr.com and used with no modifications.
{kind=link}
Setting Up Kibana for Kubernetes Logs
Now that we've discussed the importance of Kubernetes logs and the challenges involved, let's dive into setting up Kibana for effective log analysis. We'll start with the prerequisites and environment preparation.
Prerequisites and Environment Preparation
Before you can start using Kibana for Kubernetes logs, you need to ensure that your environment is ready. Here are the prerequisites:
-
A running Kubernetes cluster
-
Access to the Kubernetes command-line tool (kubectl)
-
Basic understanding of Kubernetes concepts
Once you have these prerequisites in place, you can proceed with deploying the EFK stack.
Once your environment is ready, it's time to deploy the EFK stack. The EFK stack comprises Elasticsearch, Fluentd, and Kibana, which together provide a robust solution for centralized log management.
Deploying the EFK (Elasticsearch, Fluentd, and Kibana) Stack
Deploying the EFK stack involves several steps. First, you need to create the necessary resources in your Kubernetes cluster. Here’s a step-by-step guide:
-
Deploy Elasticsearch: Elasticsearch is the data store where all your logs will be indexed and stored. You can deploy it using a StatefulSet to ensure data persistence.
-
Deploy Fluentd: Fluentd acts as the log collector and forwarder. It gathers logs from all your pods and sends them to Elasticsearch.
-
Deploy Kibana: Kibana is the visualization layer. It provides a web interface for querying and visualizing your logs stored in Elasticsearch.
Here is an example Kubernetes manifest to deploy Elasticsearch:
apiVersion: apps/v1kind: StatefulSet metadata: name: elasticsearch spec: serviceName: "elasticsearch" replicas: 1 selector: matchLabels: app: elasticsearch template: metadata: labels: app: elasticsearch spec: containers: - name: elasticsearch image: docker.elastic.co/elasticsearch/elasticsearch:7.10.1 ports: - containerPort: 9200 name: http - containerPort: 9300 name: transport
Once Elasticsearch is up and running, you can deploy Fluentd and Kibana similarly. Ensure that Fluentd is configured to forward logs to your Elasticsearch instance and that Kibana is connected to Elasticsearch for data visualization. For more insights on optimizing your Kubernetes setup, check out this guide on Kubernetes cost optimization on AWS EKS.
Configuring Kibana with Log Index Patterns
After deploying the EFK stack, the next step is to configure Kibana. This involves setting up index patterns to allow Kibana to recognize and visualize the log data stored in Elasticsearch.
To configure an index pattern in Kibana, you may also want to understand the importance of Kubernetes monitoring for comprehensive observability.
-
Open Kibana in your web browser.
-
Navigate to the "Management" section.
-
Click on "Index Patterns" and then "Create Index Pattern."
-
Enter the index pattern that matches your log indices, such as "fluentd-*" or "logstash-*."
-
Select the time filter field, typically "@timestamp."
-
Click "Create Index Pattern" to save your configuration.
With the index pattern configured, Kibana can now interpret and visualize the log data from Elasticsearch.
Analyzing Kubernetes Logs with Kibana
Now that Kibana is set up and connected to your log data, you can start analyzing your Kubernetes logs. Kibana offers powerful features for creating dashboards, visualizations, and applying filters to gain insights from your logs.
Setting Up Dashboards
Dashboards in Kibana provide a consolidated view of multiple visualizations and data points. To set up a dashboard, you might also want to explore Kubernetes monitoring with Prometheus for a comprehensive monitoring solution.
-
Navigate to the "Dashboard" section in Kibana.
-
Click on "Create Dashboard."
-
Add visualizations and saved searches to the dashboard by clicking "Add" and selecting the desired components.
-
Arrange the components as needed to create a comprehensive view of your log data.
-
Save the dashboard for future use.
Creating Visualizations
Visualizations are the core of Kibana's analytical capabilities. They allow you to transform raw log data into meaningful charts, graphs, and tables. To create a visualization:
-
Go to the "Visualize" section in Kibana.
-
Click "Create Visualization" and choose the type of visualization you want to create (e.g., bar chart, pie chart, line graph).
-
Select the data source, typically the index pattern you configured earlier.
-
Configure the visualization by selecting the metrics and buckets you want to display.
-
Save the visualization for use in dashboards or further analysis.
Applying Filters and Queries
Kibana allows you to apply filters and queries to drill down into your log data. This is essential for isolating specific issues and understanding their context. To apply filters and queries:
-
Use the search bar at the top of the Kibana interface to enter your query. For example, you can search for specific error messages or log levels.
-
Use the filter controls to add conditions, such as time ranges or specific field values.
-
Combine multiple filters and queries to narrow down the data to the most relevant entries.
By effectively using filters and queries, you can quickly identify and troubleshoot issues in your Kubernetes cluster.
Best Practices for Log Analysis
Effective log analysis goes beyond just setting up the tools. It involves following best practices to ensure that your logs provide the maximum value.
Staying on Top of Log Rotation and Retention
Log rotation and retention are crucial for managing the volume of log data. Without proper rotation, log files can grow indefinitely, consuming valuable storage space and making it difficult to find relevant information.
-
Implement log rotation policies to archive or delete old log files automatically.
-
Set retention periods based on your operational and compliance requirements.
-
Regularly monitor your log storage to ensure that it remains within acceptable limits.
Monitoring for Anomalies and Patterns
Logs can reveal patterns and anomalies that indicate potential issues or areas for improvement. By monitoring your logs proactively, you can catch problems before they escalate.
-
Set up alerts in Kibana to notify you of unusual log patterns or error rates.
-
Use machine learning features in Kibana to detect anomalies automatically.
-
Regularly review your logs for recurring issues or trends.
Correlating Logs Across Different Layers and Services
Kubernetes applications often involve multiple layers and services. Correlating logs across these layers can provide a more comprehensive understanding of issues and their root causes.
-
Use unique identifiers, such as trace IDs or session IDs, to link logs from different services.
-
Leverage Kibana's cross-index search capabilities to analyze logs from multiple sources simultaneously.
-
Visualize the flow of requests and responses across your application stack to identify bottlenecks and failures.
By following these best practices, you can enhance your log analysis capabilities and improve the overall reliability of your Kubernetes applications.
Case Studies
To illustrate the power of effective log management with Kibana, let's look at some real-world case studies. These examples showcase how organizations have successfully used the EFK stack to troubleshoot and optimize their Kubernetes deployments.
Successful Troubleshooting Scenarios
One of the most compelling examples comes from a large e-commerce company that experienced intermittent performance issues during peak shopping seasons. By leveraging the EFK stack, the company's DevOps team was able to identify and resolve the root cause quickly.
"We were facing random slowdowns that were impacting our user experience. Using Kibana, we correlated logs from different services and discovered that a specific microservice was causing the issue. Fixing that microservice improved our performance by 30% during peak times."
In another instance, a financial services firm used Kibana to troubleshoot security incidents. They set up alerts for unusual log patterns and were able to detect and mitigate a potential security breach before any significant damage occurred.
Real-World Applications and Insights
Beyond troubleshooting, effective log management with Kibana can provide valuable insights into your application's behavior and usage patterns. For example, a healthcare provider used Kibana to analyze usage trends of their telehealth platform. This analysis helped them optimize resource allocation and improve user satisfaction. For more on optimizing Kubernetes, check out this guide on Kubernetes cost optimization on AWS EKS.
"By visualizing our logs in Kibana, we noticed that user activity spiked during certain hours. This insight allowed us to allocate more resources during those times, reducing latency and improving the user experience."
These case studies highlight the transformative impact that effective log management can have on operational success. Whether it's improving performance, enhancing security, or optimizing resource allocation, the EFK stack and Kibana offer powerful tools for gaining actionable insights from your Kubernetes logs.
Final Thoughts
Effective log management is a cornerstone of successful Kubernetes operations. By mastering the use of Kubernetes logs and leveraging the EFK stack, you can gain deep insights into your applications, troubleshoot issues more efficiently, and ultimately enhance the reliability and performance of your services.
The Impact of Effective Log Management on Operational Success
Effective log management can significantly reduce downtime, improve application performance, and enhance security. By proactively monitoring and analyzing your logs, you can catch issues early, understand their root causes, and implement solutions swiftly. This not only improves your operational efficiency but also enhances the user experience and satisfaction. For more insights on monitoring, check out this guide to Kubernetes monitoring with Datadog.
Frequently Asked Questions (FAQ)
What are the primary challenges of Kubernetes log management?
The primary challenges of Kubernetes log management include handling the ephemeral nature of pods, managing the high volume and complexity of log data, and minimizing the performance impact of traditional logging methods. These challenges require robust solutions like the EFK stack to ensure effective log aggregation, storage, and analysis.
How does the EFK stack simplify Kubernetes log monitoring?
The EFK stack simplifies Kubernetes log monitoring by providing a centralized logging solution. Fluentd collects logs from all pods and forwards them to Elasticsearch, where they are indexed and stored. Kibana then provides a powerful interface for querying, visualizing, and analyzing the logs, making it easier to identify and troubleshoot issues.
Why is it essential to use Kibana for analyzing Kubernetes logs?
Kibana is essential for analyzing Kubernetes logs because it offers robust visualization and querying capabilities. It allows you to create dashboards, set up alerts, and apply filters and queries to drill down into your log data. This makes it easier to identify patterns, anomalies, and root causes of issues, ultimately improving your troubleshooting efficiency and operational success.