

Key Takeaways
Kubeflow is an open-source platform that helps manage machine learning workflows on Kubernetes, simplifying the process of building and deploying ML models.
Argo is a workflow automation tool that integrates seamlessly with Kubernetes, allowing for efficient orchestration of complex AI workflows.
MLflow provides a robust framework for tracking experiments, managing models, and streamlining the ML lifecycle within Kubernetes environments.
Seldon is designed for deploying machine learning models at scale, offering various deployment methods and ensuring high availability and performance.
TFX (TensorFlow Extended) helps create end-to-end ML pipelines, making it easier to manage and automate the entire machine learning process on Kubernetes.
Top 5 Kubernetes Native Tools for AI Workflow Orchestration
Why Kubernetes is Essential for AI Workflow Orchestration
Kubernetes has become a cornerstone for deploying and managing containerized applications, but its benefits extend far beyond just container orchestration. For AI and machine learning workflows, Kubernetes provides a scalable, reliable, and efficient environment that simplifies the management of complex tasks. The platform’s inherent capabilities, such as automatic scaling, rolling updates, and self-healing, make it an ideal choice for AI workflows that demand high availability and performance.
Moreover, Kubernetes offers seamless integration with various tools specifically designed for AI and ML workflows, allowing developers to focus more on model development and less on infrastructure management. By leveraging Kubernetes, you can orchestrate your AI workflows more effectively, ensuring that your models are always up-to-date and running smoothly.
The Challenges Faced in AI Workflow Orchestration
Orchestrating AI workflows comes with its own set of challenges. One of the primary issues is the complexity involved in managing different stages of the machine learning lifecycle, from data preprocessing to model training and deployment. Each stage requires different resources and configurations, making it difficult to maintain consistency and efficiency.
Another challenge is scalability. As the volume of data and the complexity of models grow, so does the need for scalable infrastructure that can handle these demands. Kubernetes addresses this by providing a scalable environment that can automatically adjust resources based on workload requirements.
Finally, integrating various tools and frameworks into a cohesive workflow can be daunting. Different tools often have different interfaces and requirements, making it challenging to create a seamless workflow. Kubernetes-native tools for AI help mitigate this by offering integrated solutions that work well together, simplifying the orchestration process.
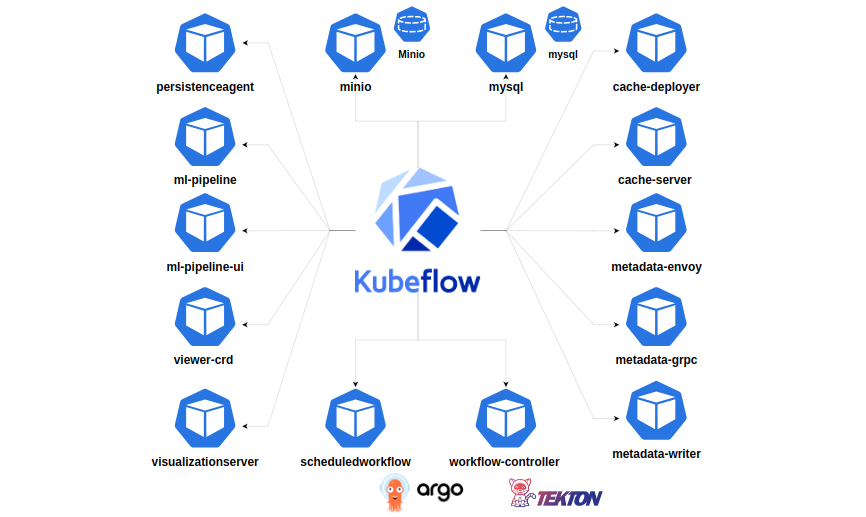
“Kubeflow Pipelines …” from medium.com and used with no modifications.
Kubeflow for Machine Learning Workflows
Overview of Kubeflow
Kubeflow is an open-source platform designed to facilitate the deployment, orchestration, and management of machine learning workflows on Kubernetes. Initially developed by Google, Kubeflow aims to make it easier to deploy scalable machine learning models and workflows, leveraging the power of Kubernetes.
The platform offers a comprehensive suite of tools for various stages of the machine learning lifecycle, including data preprocessing, model training, and deployment. With Kubeflow, you can manage your entire machine learning pipeline from a single interface, ensuring consistency and efficiency.
Core Features and Benefits
Scalability: Kubeflow leverages Kubernetes’ inherent scalability features, allowing you to scale your machine learning workloads automatically based on demand.
Portability: Kubeflow supports multiple cloud providers and on-premises environments, making it easy to move your workflows between different platforms.
Ease of Use: The platform offers a user-friendly interface and a set of pre-built components that simplify the process of building and deploying machine learning models.
Integration: Kubeflow integrates seamlessly with popular machine learning frameworks like TensorFlow, PyTorch, and Apache MXNet, providing a unified environment for your ML workflows.
Real-world Use Cases
Kubeflow has been adopted by various organizations to streamline their machine learning workflows. For instance, a leading e-commerce company uses Kubeflow to manage its recommendation engine, ensuring that the models are always up-to-date and delivering accurate recommendations to users. Another example is a healthcare provider that leverages Kubeflow to deploy predictive models for patient outcomes, improving the quality of care and operational efficiency.
These real-world use cases highlight the versatility and effectiveness of Kubeflow in managing complex machine learning workflows, making it an invaluable tool for organizations looking to scale their AI initiatives.
“Kubernetes using Argo CD …” from foxutech.com and used with no modifications.
Argo for Workflow Automation
Introduction to Argo
Argo is a powerful workflow automation tool designed to orchestrate complex workflows on Kubernetes. It offers a set of components that enable the automation of various tasks, from simple job execution to complex multi-step workflows. Argo is particularly well-suited for AI and machine learning workflows, where automation and efficiency are critical.
The tool provides a declarative approach to defining workflows, making it easy to manage and maintain them. With Argo, you can automate the entire machine learning lifecycle, from data ingestion and preprocessing to model training and deployment, ensuring that your workflows are always running smoothly and efficiently.
Key Features of Argo
Declarative Workflows: Argo allows you to define your workflows using YAML, providing a clear and concise way to manage your tasks.
Scalability: The tool leverages Kubernetes’ scalability features, enabling you to scale your workflows automatically based on demand.
Flexibility: Argo supports various types of workflows, from simple job execution to complex multi-step processes, making it a versatile tool for different use cases.
Integration: Argo integrates seamlessly with other Kubernetes-native tools, ensuring a cohesive and efficient workflow management experience.
Steps to Integrate Argo into AI Workflows
Integrating Argo into your AI workflows can streamline the entire process, from data ingestion to model deployment. Here’s a step-by-step guide to get you started:
For a comprehensive understanding of AI model lifecycle management, consider exploring AI model lifecycle management with Kubeflow on Kubernetes.
Install Argo: First, you need to install Argo on your Kubernetes cluster. You can do this using the following command:
kubectl create namespace argokubectl apply -n argo -f https://raw.githubusercontent.com/argoproj/argo/stable/manifests/install.yamlDefine Workflows: Create YAML files to define your workflows. These files will specify the sequence of tasks and the dependencies between them.
Submit Workflows: Use the Argo CLI to submit your workflows to the Kubernetes cluster. For example:
argo submit -n argo my-workflow.yamlMonitor Workflows: Monitor the progress of your workflows using the Argo UI or CLI. This allows you to track the status of each task and identify any issues that may arise.
Automate Workflows: Configure Argo to automatically trigger workflows based on specific events, such as the arrival of new data or the completion of a previous task.
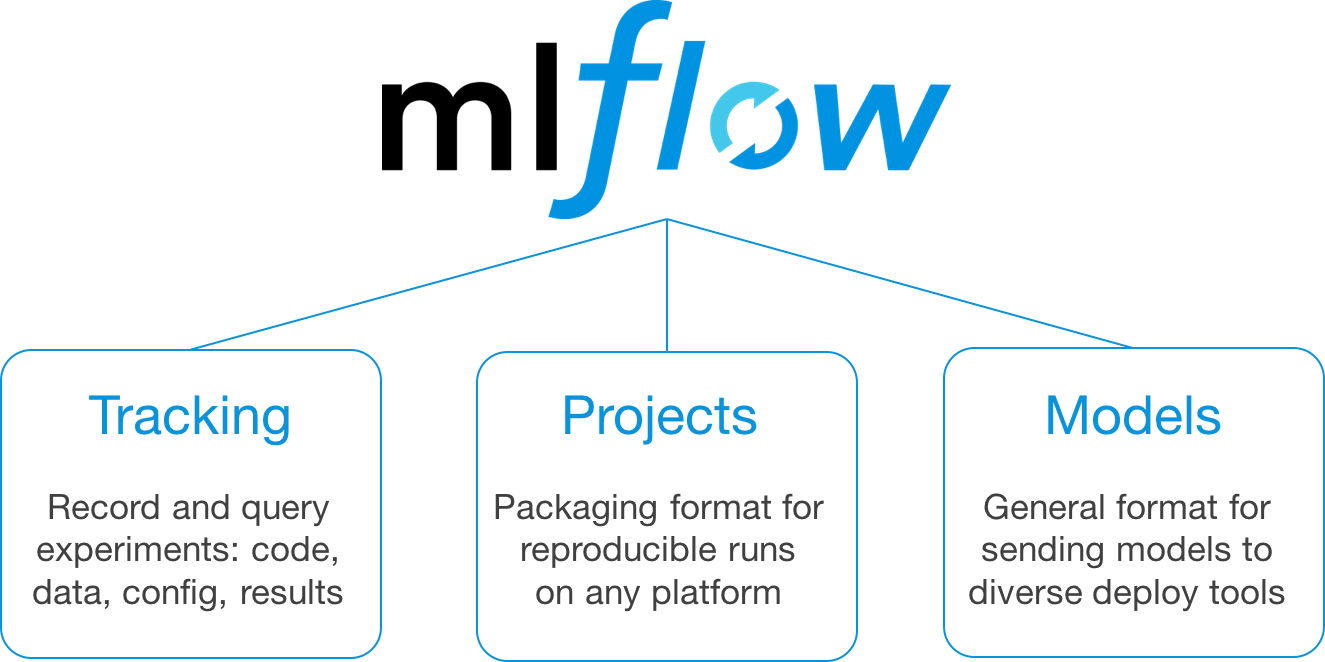
“Introducing MLflow: Open ML Platform …” from www.databricks.com and used with no modifications.
MLflow for Experiment Tracking
Experiment tracking is a crucial aspect of the machine learning lifecycle, and MLflow is one of the most effective tools for this purpose. MLflow helps you manage the entire lifecycle of your machine learning experiments, from data preparation to model deployment, ensuring that you can easily track and reproduce your results.
What is MLflow?
MLflow is an open-source platform designed to manage the end-to-end machine learning lifecycle. It provides a set of tools to help you track experiments, package code into reproducible runs, and manage and deploy models. MLflow is highly versatile and integrates seamlessly with Kubernetes, making it an ideal choice for managing machine learning workflows in containerized environments.
With MLflow, you can log various aspects of your experiments, including parameters, metrics, and artifacts. This makes it easier to compare different runs and identify the best-performing models. Additionally, MLflow’s model management capabilities allow you to version and deploy models with ease, ensuring that you can quickly move from experimentation to production.
Main Capabilities
Experiment Tracking: Log parameters, metrics, and artifacts for each run, making it easy to compare and reproduce results.
Model Management: Version and manage models, ensuring that you can easily deploy the best-performing models to production.
Reproducibility: Package code and dependencies into reproducible runs, ensuring that your experiments can be easily reproduced and shared.
Integration: Integrates seamlessly with popular machine learning frameworks and tools, such as TensorFlow, PyTorch, and Scikit-learn.
Benefits of Using MLflow in Kubernetes
Using MLflow in a Kubernetes environment offers several benefits, including scalability, portability, and ease of use. Kubernetes provides a scalable infrastructure that can automatically adjust resources based on workload demands, ensuring that your experiments run efficiently. Additionally, Kubernetes’ portability features make it easy to move your workflows between different environments, whether on-premises or in the cloud.
MLflow’s integration with Kubernetes also simplifies the process of managing and deploying models. You can use Kubernetes to orchestrate your MLflow experiments, ensuring that they run smoothly and efficiently. This allows you to focus more on developing and refining your models, rather than managing infrastructure.
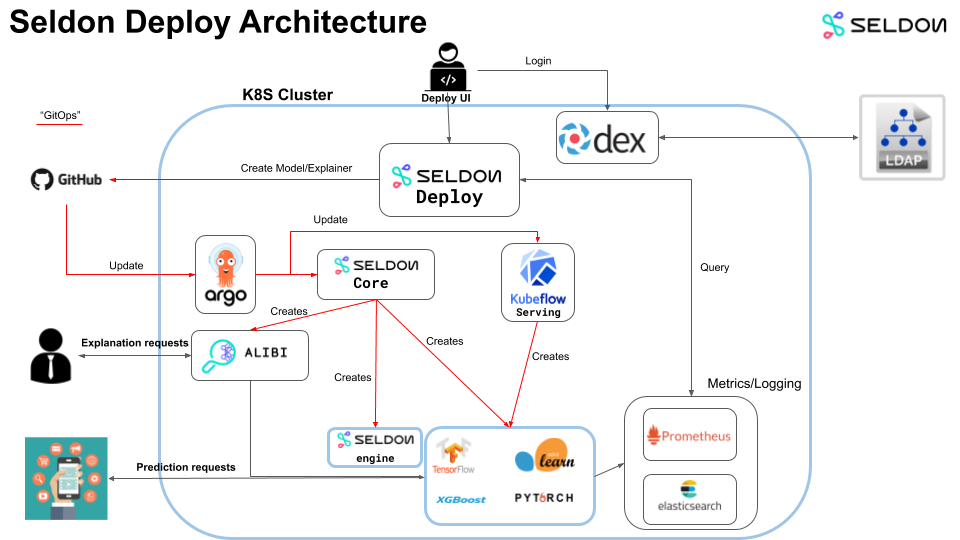
“Architecture | Seldon Deploy Docs” from deploy-v1-1.seldon.io and used with no modifications.
Seldon for Deploying Machine Learning Models
Deploying machine learning models at scale can be challenging, but Seldon makes this process much more manageable. Seldon is an open-source platform designed to deploy, scale, and manage machine learning models on Kubernetes, ensuring high availability and performance.
Introduction to Seldon
Seldon provides a robust framework for deploying machine learning models as microservices, making it easier to integrate them into your existing infrastructure. The platform supports various machine learning frameworks, including TensorFlow, PyTorch, and XGBoost, allowing you to deploy models from different sources seamlessly.
With Seldon, you can create and manage multiple model versions, perform A/B testing, and monitor model performance in real-time. This ensures that your models are always delivering accurate and reliable predictions, even as your data and requirements change.
Primary Advantages
Scalability: Leverages Kubernetes’ scalability features to deploy and manage models at scale, ensuring high availability and performance.
Flexibility: Supports various machine learning frameworks, making it easy to deploy models from different sources.
Monitoring: Provides real-time monitoring and logging capabilities, allowing you to track model performance and identify any issues quickly.
Versioning: Supports model versioning and A/B testing, ensuring that you can easily manage and update your models.
Deployment Methods with Seldon
Deploying models with Seldon is straightforward and can be done using various methods. Here’s a quick overview:
Deploying from a Model Repository: You can deploy models directly from a model repository, such as a Docker registry or a cloud storage service. This allows you to manage your models centrally and deploy them as needed.
Deploying from a Jupyter Notebook: Seldon integrates with Jupyter Notebooks, allowing you to deploy models directly from your development environment. This simplifies the process of moving from experimentation to production.
Deploying with Helm Charts: Use Helm charts to deploy Seldon and your models on Kubernetes. Helm provides a package manager for Kubernetes, making it easier to manage and update your deployments.
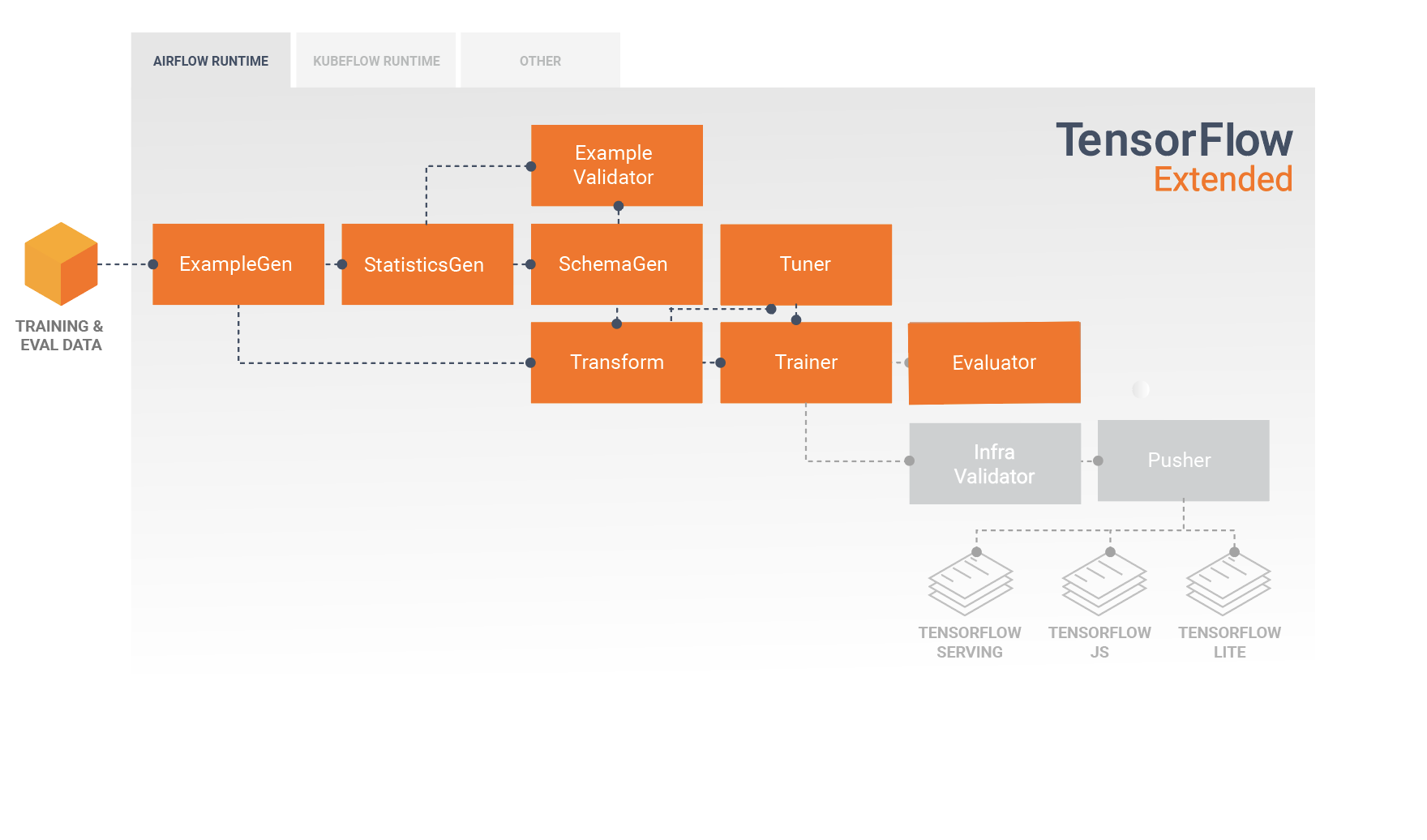
“The TFX User Guide | TensorFlow” from www.tensorflow.org and used with no modifications.
TFX (TensorFlow Extended) for End-to-End ML Pipelines
TFX, or TensorFlow Extended, is a powerful platform designed to create end-to-end machine learning pipelines. TFX provides a set of tools and libraries that help you manage the entire machine learning lifecycle, from data ingestion to model deployment, ensuring that your workflows are efficient and scalable.
Basics of TFX
TFX offers a comprehensive suite of components for building and managing machine learning pipelines. These components include:
ExampleGen: Ingests and processes raw data, converting it into a format suitable for machine learning.
Transform: Performs data preprocessing and feature engineering, ensuring that your data is ready for model training.
Trainer: Trains your machine learning models using TensorFlow, leveraging the power of distributed computing.
Evaluator: Evaluates model performance, providing insights into how well your models are performing.
Pusher: Deploys your trained models to production, ensuring that they are available for real-time predictions.
How TFX Streamlines ML Pipelines
TFX streamlines the process of building and managing machine learning pipelines by providing a set of standardized components and workflows. This ensures that your pipelines are consistent, scalable, and easy to maintain. With TFX, you can automate various stages of the machine learning lifecycle, from data ingestion and preprocessing to model training and deployment.
By leveraging TFX’s powerful tools and libraries, you can create robust and efficient machine learning pipelines that can handle large volumes of data and complex models. This makes it easier to scale your AI initiatives and ensure that your models are always delivering accurate and reliable predictions.
Optimizing AI Workflows with Kubernetes Native Tools
Leveraging Kubernetes native tools can significantly optimize AI workflows, making them more efficient and scalable. These tools help automate various stages of the machine learning lifecycle, from data ingestion and preprocessing to model training and deployment. By using Kubernetes native tools, you can ensure that your AI workflows are consistent, scalable, and easy to maintain.
Combining Tools for Maximum Efficiency
Combining multiple Kubernetes native tools can maximize the efficiency of your AI workflows. For instance, you can use Kubeflow for managing machine learning workflows, Argo for workflow automation, MLflow for experiment tracking, Seldon for deploying models, and TFX for creating end-to-end ML pipelines. Each tool offers unique capabilities that complement each other, creating a cohesive and efficient workflow management system.
Here’s how you can combine these tools for maximum efficiency:
Kubeflow: Use Kubeflow to manage your machine learning workflows, from data preprocessing to model training and deployment.
Argo: Automate your workflows with Argo, ensuring that tasks are executed efficiently and in the correct sequence.
MLflow: Track your experiments with MLflow, logging parameters, metrics, and artifacts for each run.
Seldon: Deploy your models with Seldon, ensuring high availability and performance.
TFX: Create end-to-end ML pipelines with TFX, automating various stages of the machine learning lifecycle.
Best Practices to Follow
Following best practices can help you get the most out of your Kubernetes native tools for AI workflow orchestration. Here are some tips to consider:
Start Small: Begin with a small, manageable project to familiarize yourself with the tools and their capabilities. This will help you understand how they work and how to integrate them into your workflows.
Automate Everything: Automation is key to efficiency. Use tools like Argo to automate as many tasks as possible, reducing the need for manual intervention.
Monitor Performance: Regularly monitor the performance of your workflows and models. Use tools like MLflow and Seldon to track metrics and identify any issues that may arise.
Version Control: Use version control for your models and workflows. This ensures that you can easily roll back to previous versions if needed and maintain a history of changes.
Stay Updated: Keep your tools and frameworks up-to-date to take advantage of the latest features and improvements.
Common Pitfalls and How to Avoid Them
While using Kubernetes native tools can greatly enhance your AI workflows, there are some common pitfalls to be aware of. Here’s how to avoid them:
Overcomplicating Workflows: Keep your workflows as simple as possible. Overcomplicating them can lead to increased complexity and potential errors.
Ignoring Scalability: Ensure that your workflows are designed to scale. Use Kubernetes’ scalability features to handle increased workloads and data volumes.
Neglecting Monitoring: Regularly monitor your workflows and models to identify any issues early. Use tools like MLflow and Seldon to track performance metrics.
Lack of Documentation: Document your workflows and processes thoroughly. This ensures that others can understand and maintain them, reducing the risk of errors.
Not Using Version Control: Always use version control for your models and workflows. This allows you to track changes and revert to previous versions if needed.
Frequently Asked Questions (FAQ)
Here are some common questions about using Kubernetes native tools for AI workflow orchestration:
What are the benefits of using Kubernetes for AI workflows?
Using Kubernetes for AI workflows offers several benefits:
Scalability: Kubernetes provides a scalable infrastructure that can automatically adjust resources based on workload demands.
Reliability: Kubernetes’ self-healing capabilities ensure that your workflows are always running smoothly and efficiently.
Flexibility: Kubernetes supports various tools and frameworks, making it easy to integrate them into your workflows.
Portability: Kubernetes allows you to move your workflows between different environments, whether on-premises or in the cloud.
How do I choose the right tool for my AI workflow needs?
Choosing the right tool depends on your specific needs and requirements. Here are some factors to consider:
Workflow Complexity: Consider the complexity of your workflows and choose a tool that can handle them efficiently.
Integration: Ensure that the tool integrates seamlessly with your existing infrastructure and other tools you use.
Scalability: Choose a tool that can scale with your workloads and data volumes.
Ease of Use: Look for a tool that is easy to use and offers a user-friendly interface.
Community Support: Consider the level of community support and available resources for the tool.
Can these tools be used together? If so, how?
Yes, these tools can be used together to create a cohesive and efficient AI workflow management system. Here’s an example of how to combine them:
Use Kubeflow to manage your machine learning workflows, Argo to automate the workflows, MLflow to track experiments, Seldon to deploy models, and TFX to create end-to-end ML pipelines. Each tool offers unique capabilities that complement each other, creating a comprehensive solution for managing AI workflows.
What are the costs associated with these tools?
The costs associated with these tools can vary based on several factors, including the scale of your deployments and the specific features you use. Here’s a general overview:
Kubernetes has become the de facto standard for container orchestration, making it a crucial component for managing AI workflows. By leveraging Kubernetes, organizations can efficiently scale their AI models, automate deployment processes, and ensure high availability. For those looking to manage the lifecycle of their AI models effectively, exploring Kubeflow on Kubernetes is highly recommended.


