

Key Takeaways
Environment variables in Kubernetes are dynamic values that can influence the behavior of your applications within containers.
They are crucial for managing configuration data, sensitive information, and application code efficiency.
Setting environment variables can be done using the kubectl command-line tool, or by specifying them in a YAML file.
Best practices include using Kubernetes secrets for sensitive data and leveraging the Downward API for pod information.
Understanding how to properly use environment variables can greatly improve deployment strategies and system resilience.
Defining Kubernetes Environment Variables
Think of environment variables like secret handshakes that let your applications know how to behave in different settings. In Kubernetes, these variables are key-value pairs that store important data your applications need to run correctly. They can be anything from database passwords to API keys, and they make sure your app knows what to do, whether it’s connecting to the right database or finding its way through a network.
Why Use Environment Variables?
Using environment variables is like giving your app a survival kit. It allows you to change your app’s settings without having to rewrite its code, which is super handy when you’re moving from development to production, or when you’re running multiple instances of the same app. This flexibility is a big deal in Kubernetes, where apps live in containers and need to adapt to different environments quickly and easily.
“environment-variable in kubernetes” from livebook.manning.com and used with no modifications.
Kubernetes Configurations: When to Use Environment Variables
Injecting Configuration Data
One of the main reasons to use environment variables is to feed configuration data into your app. Let’s say you have an app that needs to know where to find its database. Instead of hard-coding that information, you can use an environment variable. This way, if the database’s address changes, you just update the variable, not the app’s code.
Handling Sensitive Information
Sensitive information like passwords and API keys should never be hard-coded into your app. That’s like leaving your house keys under the mat. With environment variables, you can keep this sensitive info safe, and if you need to share your code, you won’t be giving away the keys to your kingdom.
Streamlining Application Code
By using environment variables, you can make your app’s code cleaner and more streamlined. This means less clutter and fewer chances for mistakes, because your code doesn’t need to know the nitty-gritty details of the environment it’s running in.
Step-by-Step Guide: Setting Up Environment Variables
Using kubectl Command-Line Tool
Let’s roll up our sleeves and dive into setting up environment variables with the kubectl command-line tool. It’s like the Swiss Army knife for Kubernetes, letting you interact with your clusters and control the fate of your apps with just a few commands.
For example, to set an environment variable for a deployment, you might use a command like this:
kubectl set env deployment/myapp MYSQL_ROOT_PASSWORD=my-secret-pw
This command tells Kubernetes to set the MYSQL_ROOT_PASSWORD environment variable to “my-secret-pw” for all the pods in the “myapp” deployment. It’s that simple.
Working with YAML Files
If you prefer to have everything written down, you can use a YAML file to set your environment variables. This is like leaving instructions for your app that it can read every time it starts up. You just include the environment variables in the pod’s configuration file, and Kubernetes will take care of the rest.
Here’s an example of how to set an environment variable in a YAML file:
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
spec:
containers:
– name: myapp-container
image: myapp:1.0
env:
– name: MYSQL_ROOT_PASSWORD
value: “my-secret-pw”
This snippet tells Kubernetes to create a pod with one container, and inside that container, it sets the MYSQL_ROOT_PASSWORD environment variable to “my-secret-pw”.
Updating environment variables for running pods is a bit like changing the tires on a moving car. It’s tricky, but Kubernetes gives you the tools to do it. The most common method is to update the deployment that manages the pod. Kubernetes will then apply the changes and, if necessary, replace the existing pods with new ones that have the updated environment variables.
Best Practices for Environment Variables in Kubernetes
Just like in any aspect of coding or system administration, there are best practices to follow when working with environment variables in Kubernetes. These practices help ensure that your configurations are secure, maintainable, and as error-free as possible.
One of the key practices is to keep your environment variables concise and to the point. Only include what’s necessary for your app to run. This not only reduces the chance of errors but also minimizes the exposure of sensitive information. Furthermore, you should document your environment variables well. This means commenting on your YAML files or maintaining good documentation separately so that your team knows what each variable is for.
Managing Sensitive Data with Kubernetes Secret
When it comes to sensitive data, you shouldn’t just throw it into your environment variables without a second thought. Kubernetes has a feature called ‘Secrets’ that is specifically designed for handling this kind of data. Secrets are similar to environment variables but are intended to hold confidential data. Here’s the kicker: Kubernetes stores Secrets in a more secure way than regular environment variables, and it’s designed to be more difficult for unauthorized users to access.
Strategies for Structuring Key-Value Pairs
Organizing your key-value pairs is essential for clarity and maintenance. Group related environment variables together, and use naming conventions that make it clear what each variable is and where it’s used. This helps prevent confusion and mistakes, especially when multiple people are working on the same project. It’s also helpful to use prefixes for environment variable names to indicate their purpose or the service they’re related to.
Another strategy is to externalize your configuration data into a separate configuration file or service. This way, you can change the configuration without having to redeploy your application. It’s like having a separate remote control for your TV, so you don’t have to get up to change the channel.
Utilizing the Downward API for Pod Info
The Downward API is a cool feature in Kubernetes that allows you to pass information about the pod to the containers running in the pod. This can include things like the pod name, namespace, and labels. It’s like giving your containers a little bit of self-awareness, so they know more about the environment they’re running in.
Case Studies: Environment Models in Action
Real-world examples can shine a light on how environment variables are used effectively in Kubernetes. For instance, consider a multi-tier web application with a front-end service, a back-end API, and a database. By using environment variables, the developers can easily point the front-end service to the correct API endpoint and the back-end API to the right database, without hard-coding any URLs or database connection strings into the application code.
Another case study might involve a global application that needs to serve different content based on the region it’s being accessed from. Developers can use environment variables to switch between different sets of data sources or configuration settings, depending on the region, all without changing the codebase.
Lastly, consider a continuous integration/continuous deployment (CI/CD) pipeline that deploys applications to different environments, such as development, staging, and production. Environment variables can be used to adjust settings like log verbosity or feature toggles, ensuring that the application behaves appropriately in each environment.
Front-end service uses an environment variable to locate the back-end API.
Back-end API uses an environment variable to connect to the correct database.
CI/CD pipelines use environment variables to adjust settings for different deployment environments.
Kubernetes Playgrounds: Real-World Applications
Kubernetes playgrounds are environments where you can experiment with Kubernetes without the fear of breaking anything important. They are perfect for testing out how environment variables work in different scenarios. You can play around with different configurations, see how your apps react to changes, and get a feel for the best ways to manage your variables.
Container Fields and Pod Templates
In Kubernetes, container fields and pod templates are where you define the settings for your containers and pods. This is where you can specify which environment variables your containers should use. By defining these variables in your pod templates, you ensure that every container spun up from that template has the correct environment variables set from the get-go.
Remember, managing environment variables effectively is key to creating flexible, scalable, and secure applications in Kubernetes. By following best practices and understanding their use cases, you can harness the full power of Kubernetes to run your applications smoothly and efficiently.
By now, you’ve got a solid grasp on the ins and out of environment variables in Kubernetes. But let’s drive it home with some frequently asked questions that might be lingering in your mind.
What are common Kubernetes objects that use environment variables?
Pods: The smallest deployable units that can be created and managed in Kubernetes.
Deployments: Manage a set of identical pods, ensuring they have the correct config and the right number of replicas running.
Services: An abstract way to expose an application running on a set of Pods as a network service.
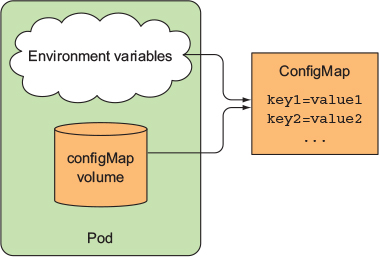
ConfigMaps: Used to store non-confidential data in key-value pairs. Pods can consume ConfigMaps as environment variables.
StatefulSets: Like Deployments, but for applications that need stable, unique network identifiers, stable persistent storage, and ordered deployment and scaling.
These Kubernetes objects allow you to manage your application’s environment dynamically and scalably, which is a fancy way of saying they help your apps adapt to different situations without a hitch.
How do I set up kubectl for environment variable management?
First things first, make sure you’ve got kubectl installed on your machine. It’s the command-line tool that lets you talk to your Kubernetes cluster. Once that’s sorted, you can use kubectl to create or modify environment variables for your pods and deployments.
For instance, to set an environment variable in a running pod, you might use:
kubectl set env pod/myapp-pod ENV_VAR_NAME=value
And to check the environment variables of a running pod, just run:
kubectl exec myapp-pod — env
These commands are your bread and butter for managing environment variables directly from your command line.
Can environment variables reference other Kubernetes secrets?
Absolutely! This is like having a secret password that opens a vault where you keep another secret password. In Kubernetes, you can reference secrets in your environment variables to keep sensitive information like database passwords or API keys secure. Here’s how:
Create a secret using kubectl or a YAML file.
Reference the secret in your pod’s environment variable configuration.
This way, you’re not hard-coding sensitive info into your app’s code or configuration files.
Is it a good practice to store API keys as environment variables?
Storing API keys as environment variables is a common practice, but it’s not without risks. It’s like keeping a spare key under the doormat; it’s convenient but not the safest option. To secure your API keys, you should use Kubernetes secrets, which are designed for storing and managing sensitive information. Secrets are encrypted during transit and at rest, which is a much more secure way to handle your precious keys.
How do environment variables work in different Kubernetes environments?
Environment variables are like chameleons; they adapt to their surroundings. In Kubernetes, you can have different sets of environment variables for different environments, like development, staging, and production. This flexibility allows you to tailor your app’s behavior based on where it’s running. For example:
In development, you might have DEBUG=true to turn on verbose logging.
In staging, you might connect to a test database.
In production, you might have more stringent security settings.
Using environment variables this way ensures that your app always has the right settings for its environment, without you needing to manually change its configuration every time you deploy.
And there you have it—a deep dive into the world of Kubernetes environment variables. From setting them up with kubectl to best practices and real-world use cases, you now have the knowledge to manage your app’s configuration like a pro. Remember, the key is to keep your environment variables clear, secure, and well-documented, and you’ll be on your way to building resilient, adaptable systems that stand the test of time.
Understanding Kubernetes deployments is crucial for running containerized applications at scale. By defining the desired state of your application within a deployment configuration, Kubernetes can manage automated rollouts and rollbacks, monitor the health of your application, and scale your services up or down based on demand.


