In the rapidly evolving field of machine learning, Large Language Models (LLMs) have emerged as a prominent tool for generating text content. However, as organizations increasingly explore the use of LLMs for sensitive data, concerns about privacy and data protection have come to the forefront. To address these concerns, an API can be utilized to communicate with an LLM service without sharing sensitive information. While training an LLM model from scratch requires extensive resources and expertise, open-source LLM models like GPT and gpt4all can be employed to evaluate their applicability to an organization’s specific needs. By leveraging these open-source models, organizations can build a private self-hosted LLM model tailor-made for their requirements. The interaction with the LLM model relies on an intelligently crafted prompt, which significantly impacts the quality of the generated results. Cloud computing infrastructure, such as Generative AI Studio and Model Garden on the Google Cloud Platform, can be valuable resources when creating a shared instance of the LLM assistant for an organization. Additionally, tools like the Python client for gpt4all enable seamless interaction with a private LLM model on a private cloud. However, launching a private LLM assistant is not the end of the journey. Further steps involve integrating the assistant with internal systems and continually enhancing its performance. If this process seems complex, fret not. SlickFinch, experts in LLM hosting and Kubernetes, can provide their expertise and support, making the journey smoother for you.

What is a self-hosted LLM
A self-hosted Large Language Model (LLM) refers to the practice of running and hosting an LLM, such as GPT or gpt4all, on your own infrastructure rather than relying on external platforms or services. LLMs have gained significant attention in the field of machine learning and natural language processing due to their ability to generate text content and interact with users.
Reasons for needing a self-hosted LLM
There are several reasons why organizations may prefer a self-hosted LLM. Firstly, privacy and data protection concerns arise when using LLMs for sensitive data. By hosting the LLM on your own infrastructure, you can ensure that sensitive information remains within the organization’s secure environment.
Secondly, relying on external APIs or services for LLM functionality can introduce dependencies and potential bottlenecks. A self-hosted LLM provides greater control and flexibility over its usage and performance, allowing organizations to tailor it to their specific needs.
Lastly, building and deploying a self-hosted LLM enables organizations to customize and extend the capabilities of the model according to their unique requirements. By having full access to the LLM, organizations can fine-tune it for their use cases and integrate it seamlessly with their existing systems.

Building a self-hosted LLM
To build a self-hosted LLM, several steps need to be taken. Firstly, it is crucial to choose an open-source LLM model, such as GPT or gpt4all, as the foundation of your self-hosted solution. These models provide a solid starting point and offer a wide range of functionalities.
Next, evaluating the fit of the chosen open-source LLM model is essential. Considering factors such as the desired use cases, the complexity and size of the model, and the specific requirements of your organization will help determine if the model aligns with your needs.
Identifying the specific use cases for the self-hosted LLM is an important step in the development process. Whether it is generating insights, assisting in code generation, or performing custom tasks, defining the use cases will guide the development and integration of the LLM.
Using a well-crafted prompt is crucial for effective interaction with the LLM model. The prompt acts as an input to the model, and how it is formulated greatly impacts the quality of the generated text. Ensuring clear and specific prompts will yield more accurate and valuable results from the LLM.
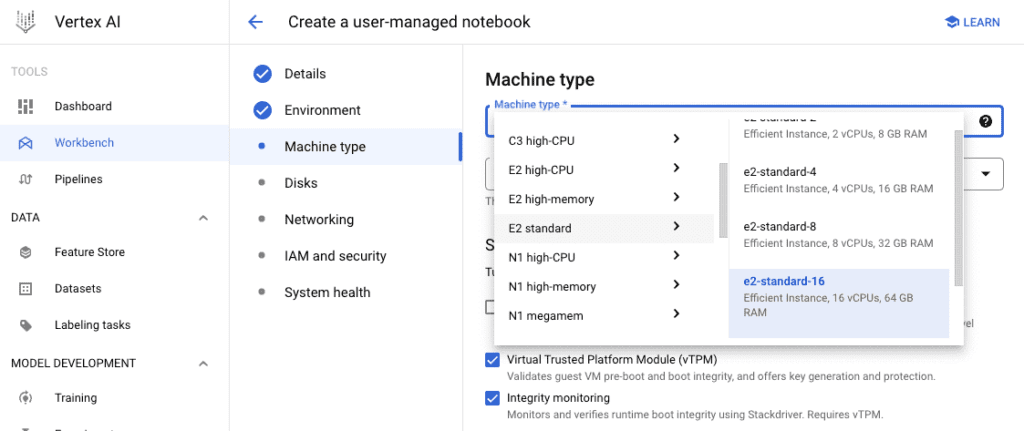
Leveraging cloud computing infrastructure for LLM hosting can be highly beneficial. Cloud platforms provide scalable and flexible resources, making it easier to manage and deploy LLM instances. Tools like Generative AI Studio and Model Garden on Google Cloud Platform offer convenient solutions for LLM development and hosting.
Furthermore, utilizing the Python client for gpt4all facilitates interaction with the private LLM model on a private cloud. This client enables smooth integration with the LLM, allowing users to interact with the model from various applications and systems.
The journey of building and deploying a self-hosted LLM
Building and deploying a self-hosted LLM involves more than just launching the model. Integration with internal systems is an essential step to ensure seamless usage and data flow between the LLM and existing infrastructure. This integration allows the LLM to become a valuable component of the organization’s ecosystem.
Once integrated, enhancing the performance of the self-hosted LLM becomes crucial. Fine-tuning the model, optimizing the underlying infrastructure, and continuously monitoring and evaluating its performance ensure consistent and efficient use of the LLM.

Why Kubernetes is the best choice for LLM hosting
When it comes to hosting an LLM, Kubernetes stands out as an ideal choice. Kubernetes is an open-source container orchestration platform that provides unparalleled scalability, flexibility, and resource management capabilities.
The scalability and flexibility offered by Kubernetes are particularly advantageous for LLM hosting. As the demand for LLM instances fluctuates, Kubernetes can automatically scale the resources up or down to meet the requirements. This ensures that the LLM is always available and responsive, regardless of the workload.
Efficient resource management is a key aspect of LLM hosting. Kubernetes optimizes resource allocation, ensuring that computational resources are utilized effectively. By efficiently distributing the workload across multiple nodes, Kubernetes maximizes the performance of the LLM and minimizes resource wastage.
High availability and fault tolerance are critical for LLM hosting. Kubernetes provides robust mechanisms for fault detection, recovery, and load balancing. This high availability ensures that the LLM remains accessible even in the event of failures or disruptions, guaranteeing uninterrupted service.
Deploying and scaling LLM instances are made effortless with Kubernetes. Its declarative configuration allows for easy deployment, replication, and management of LLM instances. This streamlines the process of setting up and expanding the LLM infrastructure, providing a smooth and efficient hosting experience.
Benefits of building a self-hosted LLM on Kubernetes
Building a self-hosted LLM on Kubernetes offers several key benefits. Firstly, it enhances the security and privacy of sensitive data. By hosting the LLM internally, organizations can maintain control over their data, ensuring that it remains within their secure environment.
Additionally, a self-hosted LLM on Kubernetes seamlessly integrates with existing Kubernetes infrastructure. This integration simplifies the management of LLM instances, as administrators can leverage their familiarity with Kubernetes tools and techniques.
The utilization of computational resources is optimized with a self-hosted LLM on Kubernetes. Kubernetes efficiently manages the allocation of resources, preventing underutilization or overloading. This optimization allows organizations to achieve maximum performance and cost-effectiveness from their LLM infrastructure.
Finally, centralized management and monitoring of LLM instances are facilitated by building on Kubernetes. Kubernetes provides comprehensive management and monitoring capabilities, enabling administrators to easily track and control multiple LLM instances from a centralized dashboard.

SlickFinch: Experts in self-hosted LLM and Kubernetes
Building and deploying a self-hosted LLM on Kubernetes can be a complex task, requiring expertise in both LLM hosting and Kubernetes. That’s where SlickFinch comes in. With our proven experience in LLM deployment and Kubernetes management, we can guide you through the process and ensure a successful implementation.
Whether you are looking to build a self-hosted LLM to leverage its capabilities for generating insights, enhancing code generation, or performing custom tasks, SlickFinch has the knowledge and expertise to help. Our team of experts will collaborate with your organization to understand your requirements and design a tailored solution that meets your specific needs.
Don’t let the complexities of LLM hosting and Kubernetes management hold you back. Contact SlickFinch today and let us take care of building and deploying your self-hosted LLM, so you can focus on leveraging its power to drive innovation and achieve your goals.