Key Takeaways
-
Kubeflow is an open-source platform that simplifies the deployment and management of machine learning workflows on Kubernetes.
-
It integrates various tools and frameworks like Jupyter Notebooks, TensorFlow, and PyTorch to streamline the ML lifecycle.
-
Kubeflow Pipelines allow for the automation of complex ML workflows, making it easier to develop, deploy, and manage models.
-
The platform can be deployed on various infrastructures, including AWS, Google Cloud, and on-premises systems.
-
Kubeflow's robust architecture enhances collaboration, experimentation, and scalability in ML projects.
Inside the Design: The Robust Architecture of Kubeflow for Machine Learning
Kubeflow has emerged as a powerful tool for managing the end-to-end machine learning (ML) lifecycle. Built on Kubernetes, it allows data scientists and ML engineers to develop, deploy, and manage models efficiently. Let's dive into why Kubeflow is a game-changer in the ML space and how its architecture supports robust and scalable workflows.
Why Kubeflow Matters in Machine Learning
Machine learning projects can be incredibly complex, involving multiple stages from data preprocessing to model deployment. Kubeflow simplifies this process by providing a unified platform that integrates various tools and frameworks. This not only streamlines workflows but also ensures that models can be easily scaled and managed.
Key Features and Components of Kubeflow
Kubeflow is packed with features designed to make the ML lifecycle more manageable. Some of its key components include:
-
Jupyter Notebooks for interactive development
-
TensorFlow Extended (TFX) and PyTorch for model training
-
Kubeflow Pipelines for workflow management
-
Tools for deploying models on different platforms
-
Components for monitoring and maintaining models
"Building Your First Kubeflow Pipeline ..." from huggingface.co and used with no modifications.
{kind=link}
The Foundation of Kubeflow
Understanding the foundation of Kubeflow is crucial for leveraging its full potential. At its core, Kubeflow is built on Kubernetes, which provides the necessary infrastructure for deploying, scaling, and managing ML workflows.
Kubernetes: The Backbone of Kubeflow
Kubernetes is an open-source platform designed for automating the deployment, scaling, and operation of application containers. In the context of Kubeflow, Kubernetes serves as the backbone that supports the various components and tools integrated into the platform. This makes it easier to manage resources, ensure scalability, and maintain high availability.
The Role of Containers in Kubeflow
Containers play a pivotal role in Kubeflow's architecture. They encapsulate the various components and tools, making it easier to deploy and manage them. This containerization ensures that each component can run independently, reducing the risk of conflicts and making it easier to scale specific parts of the workflow as needed.
Breaking Down Kubeflow's Components
Kubeflow is composed of several key components, each designed to address a specific aspect of the ML lifecycle. Let's take a closer look at some of these components and how they contribute to the overall robustness of the platform.
Jupyter Notebooks for Interactive Development
Jupyter Notebooks are an essential tool for data scientists, providing an interactive environment for data exploration, visualization, and experimentation. In Kubeflow, Jupyter Notebooks are integrated seamlessly, allowing users to develop and test their models interactively before moving on to more complex stages like training and deployment.
TensorFlow Extended (TFX) and PyTorch Integration
Kubeflow supports various machine learning frameworks, including TensorFlow and PyTorch. TensorFlow Extended (TFX) is particularly notable for its comprehensive suite of tools designed for end-to-end ML pipelines. By integrating these frameworks, Kubeflow ensures that users can leverage the best tools for their specific needs, whether it's training a model or deploying it in a production environment.
Kubeflow Pipelines for Workflow Management
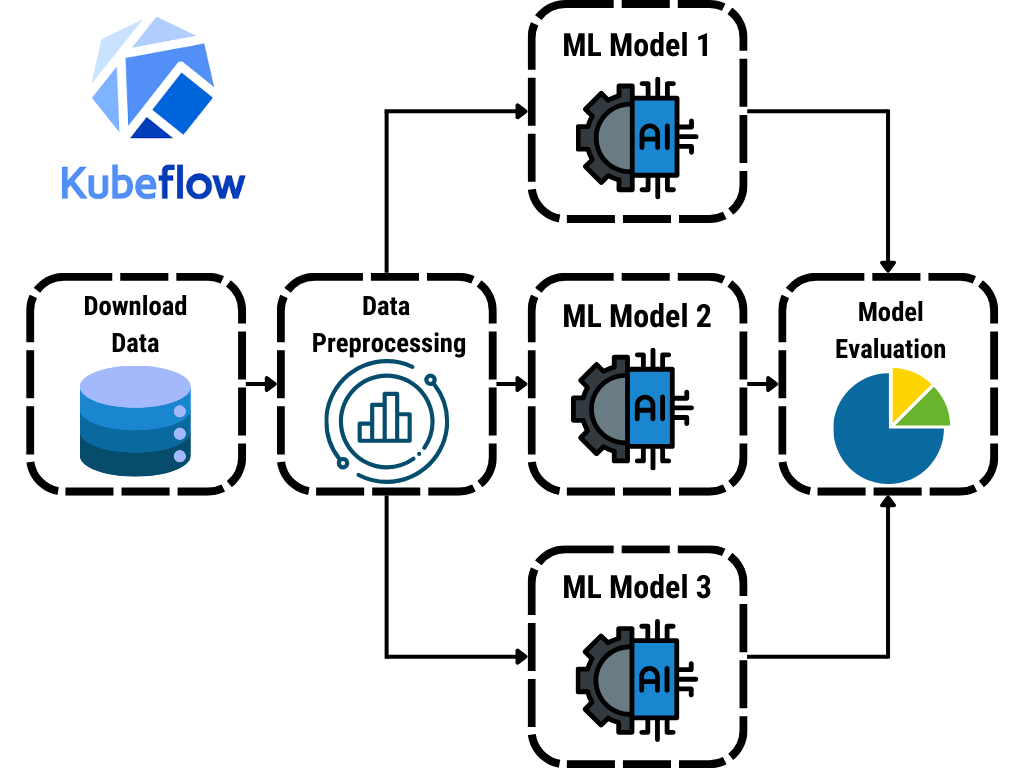
Kubeflow Pipelines are one of the platform's most powerful features. They allow users to define, automate, and monitor complex ML workflows. This automation not only saves time but also reduces the risk of errors, making it easier to maintain high-quality models over time.
Creating Pipelines
Creating a pipeline in Kubeflow involves defining the various steps of your ML workflow, from data preprocessing to model evaluation. These steps are then executed in a defined sequence, ensuring that each stage of the workflow is completed before moving on to the next. This structured approach makes it easier to manage and optimize the entire ML lifecycle.
Kubeflow Pipelines also offer a visual interface for managing and monitoring workflows. This interface provides a clear overview of each pipeline's status, making it easier to identify and address any issues that may arise during execution. Additionally, Kubeflow Pipelines support versioning, allowing users to track changes and revert to previous versions if needed.
Managing Experiments
Experimentation is a crucial aspect of machine learning, and Kubeflow provides robust tools for managing experiments. Users can easily track different versions of their models, compare results, and select the best-performing models for deployment. This level of control ensures that the best models are always in production, leading to more accurate and reliable outcomes.
Deploying Kubeflow on Different Platforms
One of the key strengths of Kubeflow is its flexibility in deployment. Whether you're using a cloud provider like AWS or Google Cloud, or prefer an on-premises setup, Kubeflow can be configured to meet your needs. Let's explore how to deploy Kubeflow on different platforms.
Installing Kubeflow on AWS
Deploying Kubeflow on AWS involves several steps. First, you'll need to set up an Amazon EKS (Elastic Kubernetes Service) cluster. Once the cluster is ready, you can use the Kubeflow deployment scripts to install the necessary components. The process typically involves:
-
Creating an EKS cluster using the AWS Management Console or CLI
-
Configuring kubectl to interact with your EKS cluster
-
Deploying the Kubeflow manifests using kustomize or the provided deployment scripts
-
Verifying the installation by accessing the Kubeflow dashboard
Setting Up Kubeflow on Google Cloud Platform
Google Cloud Platform (GCP) is another popular choice for deploying Kubeflow. GCP offers Google Kubernetes Engine (GKE), which simplifies the process of setting up and managing Kubernetes clusters. To deploy Kubeflow on GCP, follow these steps:
-
Create a GKE cluster using the GCP Console or gcloud CLI
-
Configure kubectl to connect to your GKE cluster
-
Deploy the Kubeflow components using the provided kustomize scripts
-
Access the Kubeflow dashboard to verify the installation
Implementing Kubeflow on On-Premise Infrastructure
If you prefer to keep your ML workflows on-premises, Kubeflow can be deployed on your local Kubernetes cluster. This setup is ideal for organizations with strict data security requirements or those looking to leverage existing infrastructure. To implement Kubeflow on-premises, follow these steps:
-
Set up a Kubernetes cluster using tools like kubeadm, Minikube, or a managed Kubernetes solution
-
Install kubectl and configure it to interact with your cluster
-
Deploy the Kubeflow components using kustomize or the provided deployment scripts
-
Verify the installation by accessing the Kubeflow dashboard
Scaling and Orchestrating Machine Learning Workloads
One of the primary benefits of using Kubeflow is its ability to scale and orchestrate machine learning workloads effectively. This is particularly important for organizations that need to handle large volumes of data or run complex models.
Automating Model Training and Deployment
Automation is a key feature of Kubeflow, allowing users to streamline the process of training and deploying models. By defining pipelines, users can automate repetitive tasks, ensuring that models are trained and deployed consistently and efficiently. This not only saves time but also reduces the risk of human error.
For example, a typical pipeline might include steps for data preprocessing, model training, evaluation, and deployment. Once the pipeline is defined, it can be executed automatically, with each step triggered by the completion of the previous one. This ensures that the entire workflow is completed in a timely and efficient manner.
Managing Resource Allocation
Effective resource management is crucial for scaling ML workloads. Kubeflow leverages Kubernetes' built-in resource management capabilities to ensure that resources are allocated efficiently. Users can define resource requirements for each component, ensuring that critical tasks receive the necessary resources while minimizing waste.
For instance, you can specify the amount of CPU and memory required for each step in your pipeline. Kubernetes will then allocate these resources accordingly, ensuring that each task has the resources it needs to run efficiently. This dynamic allocation helps optimize resource usage and ensures that your infrastructure can handle varying workloads.
Case Studies: Real-World Applications of Kubeflow
To truly understand the impact of Kubeflow, let's look at some real-world examples of how organizations are using the platform to enhance their machine learning workflows.
Case Study 1: Healthcare Industry
In the healthcare industry, accurate and timely predictions can save lives. One healthcare provider used Kubeflow to develop a predictive model for identifying patients at risk of sepsis. By leveraging Kubeflow's robust architecture, they were able to automate the entire ML pipeline, from data ingestion to model deployment.
"With Kubeflow, we reduced the time to deploy new models from weeks to days, allowing us to respond more quickly to emerging healthcare challenges."
The result was a more efficient and accurate system for predicting sepsis, ultimately leading to better patient outcomes.
Case Study 2: Financial Services
Financial institutions rely heavily on machine learning for tasks like fraud detection and risk assessment. One major bank used Kubeflow to streamline their ML workflows, enabling them to deploy models more quickly and efficiently.
"Kubeflow allowed us to automate our model training and deployment processes, significantly reducing the time it takes to get new models into production."
This automation not only improved the bank's ability to detect fraud but also enhanced their overall risk management strategies.
Case Study 3: E-commerce and Retail
In the e-commerce and retail sectors, personalized recommendations are key to driving sales. One online retailer used Kubeflow to develop a recommendation engine that analyzes customer behavior and suggests products in real-time.
"By using Kubeflow, we were able to deploy our recommendation engine quickly and scale it to handle millions of users, providing a better shopping experience for our customers."
The result was a significant increase in customer engagement and sales, demonstrating the power of Kubeflow in real-world applications.
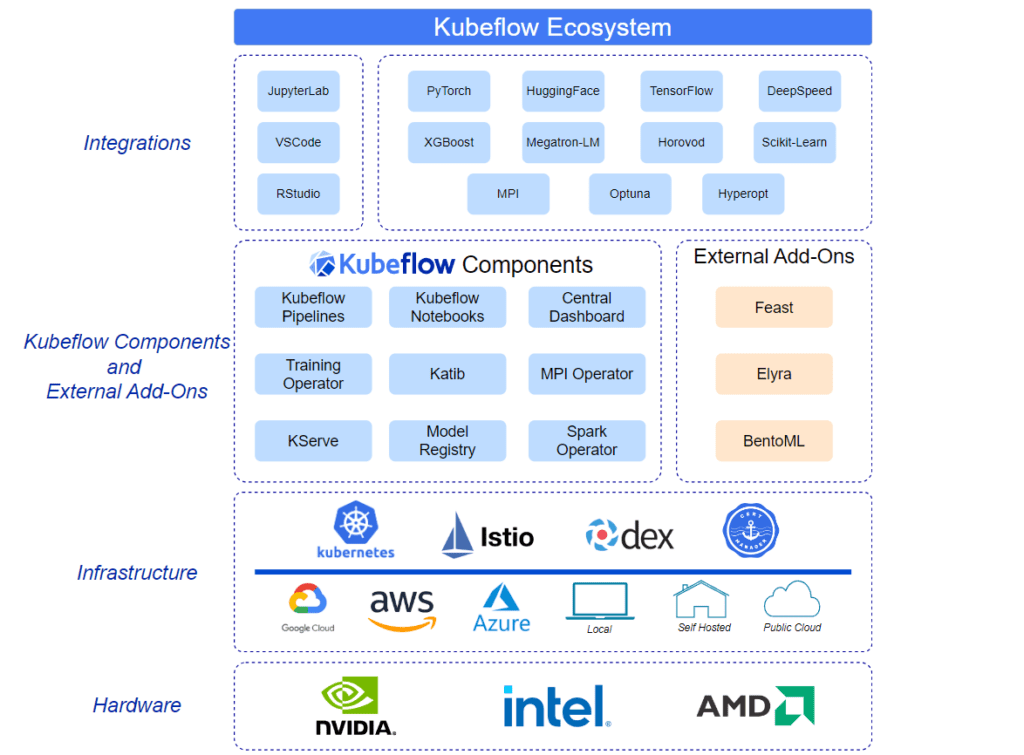
"Kubeflow Ecosystem" from kubeflow.org and used with no modifications.
Benefits of Using Kubeflow for Machine Learning Projects
Kubeflow offers numerous benefits for organizations looking to enhance their machine learning workflows. Here are some of the key advantages:
Increased Collaboration
Kubeflow fosters collaboration by providing a unified platform where data scientists, ML engineers, and DevOps teams can work together seamlessly. This collaborative environment ensures that everyone is on the same page, leading to more efficient and effective workflows.
Enhanced Experimentation and Tracking
Experimentation is a crucial aspect of machine learning, and Kubeflow provides robust tools for tracking experiments. Users can easily compare different versions of their models, track performance metrics, and select the best models for deployment. This level of control ensures that the best models are always in production, leading to more accurate and reliable outcomes.
Improved Scaling and Flexibility
Kubeflow's integration with Kubernetes provides powerful scaling capabilities, allowing organizations to handle large volumes of data and run complex models efficiently. Additionally, Kubeflow's flexibility in deployment ensures that it can be used on various infrastructures, from cloud providers to on-premises systems.
Enhanced Experimentation and Tracking
Experimentation is a crucial aspect of machine learning, and Kubeflow provides robust tools for tracking experiments. Users can easily compare different versions of their models, track performance metrics, and select the best models for deployment. This level of control ensures that the best models are always in production, leading to more accurate and reliable outcomes.
Improved Scaling and Flexibility
Kubeflow's integration with Kubernetes provides powerful scaling capabilities, allowing organizations to handle large volumes of data and run complex models efficiently. Additionally, Kubeflow's flexibility in deployment ensures that it can be used on various infrastructures, from cloud providers to on-premises systems.
Besides that, the platform's containerized architecture ensures that each component can run independently, making it easier to scale specific parts of the workflow as needed. This flexibility is particularly valuable for organizations with varying workloads and resource requirements.
Conclusion: Embracing the Power of Kubeflow
In conclusion, Kubeflow represents a significant advancement in the field of machine learning. Its robust architecture, built on Kubernetes, provides a powerful platform for managing the entire ML lifecycle, from development to deployment. By integrating various tools and frameworks, Kubeflow simplifies complex workflows and enhances collaboration, experimentation, and scalability.
-
Kubeflow simplifies the deployment and management of ML workflows on Kubernetes.
-
It integrates tools like Jupyter Notebooks, TensorFlow, and PyTorch for streamlined ML processes.
-
Kubeflow Pipelines automate complex workflows, reducing time and errors.
-
The platform supports deployment on AWS, Google Cloud, and on-premises systems.
-
Kubeflow enhances collaboration, experimentation, and scalability in ML projects.
As organizations continue to embrace machine learning, the need for robust and scalable platforms like Kubeflow will only grow. By leveraging Kubeflow's powerful features and capabilities, organizations can accelerate their ML projects, improve model accuracy, and ultimately drive better business outcomes.
Future Trends and Developments
Looking ahead, several trends and developments are likely to shape the future of Kubeflow and machine learning in general. One key trend is the increasing use of AI and ML in various industries, from healthcare to finance to retail. As more organizations adopt these technologies, the demand for platforms like Kubeflow will continue to rise.
"The future of machine learning lies in automation, scalability, and integration, and Kubeflow is well-positioned to lead the way."
Another important trend is the growing emphasis on model interpretability and fairness. As machine learning models become more complex, ensuring that they are transparent and unbiased will be critical. Kubeflow's robust tracking and experimentation tools can help organizations address these challenges by providing greater visibility into model performance and behavior.
Finally, advancements in cloud computing and containerization will continue to drive innovation in the ML space. As these technologies evolve, Kubeflow will likely integrate new features and capabilities to stay at the forefront of the industry.
Frequently Asked Questions (FAQ)
To help you get started with Kubeflow and address some common questions, we've compiled a list of frequently asked questions.
What are the prerequisites for installing Kubeflow?
Before installing Kubeflow, you'll need to have a Kubernetes cluster set up and running. This can be done using tools like kubeadm, Minikube, or a managed Kubernetes service like Amazon EKS or Google Kubernetes Engine (GKE). Additionally, you'll need to install kubectl, the Kubernetes command-line tool, and configure it to interact with your cluster.
"Ensure your Kubernetes cluster is properly configured and has sufficient resources to support the Kubeflow components."
Can Kubeflow be used with other machine learning frameworks?
Yes, Kubeflow supports various machine learning frameworks, including TensorFlow, PyTorch, and Apache MXNet. This flexibility allows users to choose the best tools for their specific needs and integrate them seamlessly into their ML workflows. For more information, check out this article on AI Kubernetes Machine Learning with Kubeflow.
Therefore, whether you're working with deep learning models in TensorFlow or experimenting with PyTorch, Kubeflow provides the necessary tools and infrastructure to support your projects.
How does Kubeflow handle model monitoring and maintenance?
Kubeflow includes several tools for monitoring and maintaining models in production. These tools provide real-time insights into model performance, allowing users to detect and address issues quickly. Additionally, Kubeflow supports versioning, enabling users to track changes and revert to previous versions if needed.
This comprehensive monitoring and maintenance framework ensures that models remain accurate and reliable over time, even as data and requirements change.
Is Kubeflow suitable for small-scale projects?
While Kubeflow is designed to handle large-scale ML workloads, it can also be used for smaller projects. The platform's modular architecture allows users to deploy only the components they need, making it a flexible and scalable solution for projects of all sizes.
Besides that, Kubeflow's user-friendly interface and robust tracking tools make it an excellent choice for teams looking to streamline their ML workflows, regardless of project size.
What support resources are available for Kubeflow users?
Kubeflow has a vibrant community of users and developers who provide support and contribute to the project's ongoing development. Users can access a wealth of resources, including documentation, tutorials, and forums, to help them get started and troubleshoot any issues they encounter.
Additionally, many cloud providers offer managed Kubeflow services, providing additional support and resources for users deploying Kubeflow on their platforms.
In conclusion, Kubeflow represents a significant advancement in the field of machine learning. Its robust architecture, built on Kubernetes, provides a powerful platform for managing the entire ML lifecycle, from development to deployment. By integrating various tools and frameworks, Kubeflow simplifies complex workflows and enhances collaboration, experimentation, and scalability. As organizations continue to embrace machine learning, the need for robust and scalable platforms like Kubeflow will only grow. By leveraging Kubeflow's powerful features and capabilities, organizations can accelerate their ML projects, improve model accuracy, and ultimately drive better business outcomes.