Key Takeaways
-
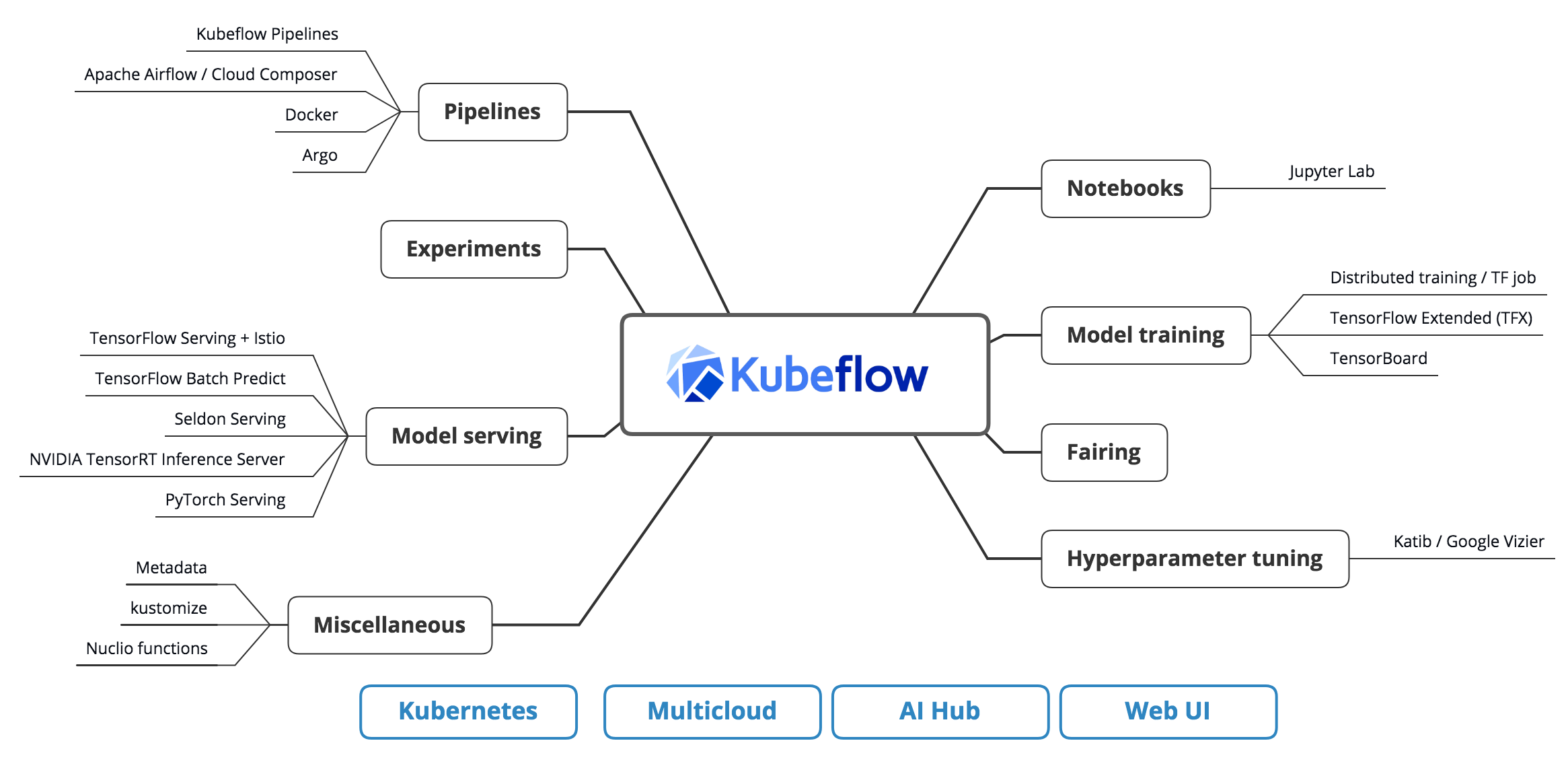
Kubeflow is an open-source platform for managing machine learning workflows on Kubernetes, ensuring scalability and portability.
-
It offers components like Kubeflow Pipelines for orchestrating workflows and Katib for hyperparameter tuning, simplifying the AI model lifecycle.
-
Setting up Kubeflow on Kubernetes requires specific prerequisites and a step-by-step installation process.
-
Kubeflow supports distributed training with TensorFlow, enabling efficient model training across multiple nodes.
-
Proper configuration of Kubeflow ensures optimal performance tailored to your specific environment.
The Power of AI Model Lifecycle Management with Kubeflow on Kubernetes
Overview of AI Model Lifecycle Management
Managing the lifecycle of an AI model involves several critical stages, from initial development to deployment and ongoing maintenance. This process includes data collection, model training, hyperparameter tuning, validation, deployment, and monitoring. Efficient management of these stages is crucial to ensure the model's performance and reliability over time.
One of the significant challenges in AI model lifecycle management is the complexity and scale of operations, especially when dealing with large datasets and multiple models. This is where Kubeflow, an open-source platform designed for Kubernetes, comes into play. Kubeflow simplifies the management of machine learning workflows, making it easier to build, train, and deploy models at scale.
The Role of Kubernetes in AI Model Management
Kubernetes is a powerful system for automating the deployment, scaling, and management of containerized applications. In the context of AI model management, Kubernetes provides the necessary infrastructure to handle the complex workflows involved in machine learning projects. By leveraging Kubernetes, organizations can ensure that their AI models are scalable, portable, and easily manageable.
Besides that, Kubernetes offers features like automatic scaling, self-healing, and rolling updates, which are essential for maintaining the performance and availability of AI models. These features make Kubernetes an ideal platform for deploying and managing machine learning workflows, ensuring that models can be efficiently trained, deployed, and monitored in a production environment.
Why Choose Kubeflow for AI Model Lifecycle
Kubeflow is specifically designed to simplify the deployment and management of machine learning workflows on Kubernetes. It provides a comprehensive set of tools and frameworks that enable data scientists and ML engineers to build, train, and deploy models more efficiently. Here are some reasons why Kubeflow is an excellent choice for AI model lifecycle management:
-
Scalability: Kubeflow leverages Kubernetes' robust infrastructure to ensure that machine learning workflows can scale seamlessly.
-
Portability: Kubeflow's components are designed to be portable, making it easy to move workflows between different environments.
-
Modularity: Kubeflow offers a modular architecture, allowing users to pick and choose the components that best fit their needs.
-
Community Support: As an open-source project, Kubeflow has a vibrant community that continuously contributes to its development and improvement.
"Workflow Management with Kubeflow" from www.analyticsvidhya.com and used with no modifications.
{kind=link}
Core Components of Kubeflow
Kubeflow Pipelines: Orchestrating ML Workflows
Kubeflow Pipelines is a powerful tool for designing, deploying, and managing end-to-end machine learning workflows. It provides a platform for building and deploying reusable and scalable pipelines, enabling teams to automate the various stages of the ML lifecycle. With Kubeflow Pipelines, you can define complex workflows as a series of steps, each representing a distinct task in the model development process.
Most importantly, Kubeflow Pipelines supports versioning and reproducibility, ensuring that experiments can be tracked and replicated easily. This feature is crucial for maintaining the integrity of your machine learning projects and ensuring that models can be reliably reproduced in different environments.
Katib: Hyperparameter Tuning
Hyperparameter tuning is a critical aspect of machine learning model development. It involves finding the optimal set of hyperparameters that maximize the model's performance. Katib, a component of Kubeflow, simplifies this process by providing an automated framework for hyperparameter tuning. With Katib, you can define and run hyperparameter tuning experiments, leveraging various optimization algorithms to find the best hyperparameters for your model.
Katib supports multiple machine learning frameworks, including TensorFlow, PyTorch, and XGBoost, making it a versatile tool for any ML project. By automating hyperparameter tuning, Katib saves time and resources, allowing data scientists to focus on other critical aspects of model development.
TFJob: Distributed Training with TensorFlow
Training machine learning models, especially deep learning models, often requires significant computational resources. Distributed training allows you to leverage multiple machines to train models more efficiently. TFJob, a Kubeflow component, enables distributed training with TensorFlow, making it easier to scale your training processes across multiple nodes. Learn more about the architecture of Kubeflow for machine learning.
TFJob handles the orchestration of distributed training jobs, ensuring that the necessary resources are allocated and managed effectively. This component is particularly useful for large-scale machine learning projects that require substantial computational power to train complex models.
Setting up Kubeflow on Kubernetes
Prerequisites for Installation
Before setting up Kubeflow on Kubernetes, there are a few prerequisites you need to fulfill. These include:
-
A Kubernetes cluster with at least one master node and multiple worker nodes.
-
kubectl, the Kubernetes command-line tool, installed on your local machine.
-
A supported version of Kubernetes (1.14 or later).
-
Sufficient computational resources to handle the Kubeflow components and your machine learning workloads.
Step-by-Step Installation Guide
Installing Kubeflow on Kubernetes involves several steps. Follow this guide to get started:
-
Set up your Kubernetes cluster: If you don't already have a Kubernetes cluster, you can create one using a cloud provider like Google Kubernetes Engine (GKE), Amazon Elastic Kubernetes Service (EKS), or Azure Kubernetes Service (AKS). Alternatively, you can set up a local cluster using tools like Minikube or Podman.
-
Install kubectl: Ensure that kubectl is installed on your local machine and configured to communicate with your Kubernetes cluster. You can download and install kubectl from the official Kubernetes website.
-
Download the Kubeflow manifests: Kubeflow provides a set of manifests that define the various components and their configurations. You can download these manifests from the Kubeflow GitHub repository.
-
Deploy Kubeflow: Use the kubectl command to deploy the Kubeflow components to your Kubernetes cluster. This process involves applying the downloaded manifests to your cluster.
-
Verify the installation: After deploying Kubeflow, verify that all components are running correctly by checking the status of the pods and services in your cluster.
Configuring Kubeflow for Your Environment
Once Kubeflow is installed, you need to configure it to suit your specific environment and requirements. This involves setting up authentication and authorization, configuring resource limits, and integrating with external data sources and storage systems. Proper configuration ensures that Kubeflow operates efficiently and securely, providing a robust platform for managing your AI model lifecycle.
Configuring Kubeflow for Your Environment
Configuring Kubeflow to match your specific needs is crucial for maximizing its efficiency and effectiveness. This involves setting up authentication and authorization, configuring resource limits, and integrating with external data sources and storage systems. Here are some key steps to follow:
-
Authentication and Authorization: Secure your Kubeflow deployment by configuring authentication mechanisms such as OAuth or LDAP. This ensures that only authorized users can access and manage your machine learning workflows.
-
Resource Limits: Set resource limits for each component in Kubeflow to prevent any single component from consuming excessive resources. This helps maintain the overall performance and stability of your Kubernetes cluster.
-
Data Integration: Integrate Kubeflow with external data sources and storage systems, such as Google Cloud Storage or Amazon S3. This allows you to seamlessly access and manage your data within Kubeflow.
Proper configuration ensures that Kubeflow operates efficiently and securely, providing a robust platform for managing your AI model lifecycle.
Managing AI Model Development
Building and Training Models with Kubeflow
Building and training machine learning models is a core aspect of the AI model lifecycle. With Kubeflow, you can streamline this process using its various components and tools. Here are the steps to build and train models with Kubeflow:
-
Data Preparation: Prepare your dataset by cleaning and preprocessing it. This step is crucial to ensure that your data is suitable for training your model.
-
Define the Model: Use a machine learning framework like TensorFlow, PyTorch, or XGBoost to define your model architecture. Kubeflow supports multiple frameworks, allowing you to choose the one that best fits your needs.
-
Train the Model: Use Kubeflow's TFJob component to train your model on a distributed cluster. This allows you to leverage the computational power of multiple nodes, speeding up the training process.
-
Evaluate the Model: After training, evaluate your model's performance using validation data. This step helps you assess the model's accuracy and identify any potential issues.
By following these steps, you can efficiently build and train machine learning models using Kubeflow, ensuring that they are ready for deployment.
Hyperparameter Tuning with Katib
Hyperparameter tuning is essential for optimizing the performance of your machine learning models. Katib, a component of Kubeflow, automates this process by running experiments to find the best hyperparameters. Here's how to use Katib for hyperparameter tuning:
-
Define the Search Space: Specify the range of values for each hyperparameter you want to tune. This defines the search space for Katib to explore.
-
Choose an Optimization Algorithm: Select an optimization algorithm, such as random search, grid search, or Bayesian optimization. Katib supports multiple algorithms, allowing you to choose the one that best fits your needs.
-
Run the Experiment: Launch the hyperparameter tuning experiment using Katib. Katib will automatically run multiple trials, testing different combinations of hyperparameters.
-
Analyze the Results: Review the results of the experiment to identify the best hyperparameters for your model. Katib provides detailed metrics and logs for each trial, making it easy to analyze the performance of different hyperparameter combinations.
By automating hyperparameter tuning with Katib, you can save time and resources while ensuring that your models are optimized for the best performance.
Monitoring Model Performance
Monitoring the performance of your machine learning models is crucial for maintaining their accuracy and reliability over time. Kubeflow provides various tools and features to help you monitor your models effectively. Here are some key aspects of model monitoring:
-
Performance Metrics: Track key performance metrics, such as accuracy, precision, recall, and F1 score, to assess the performance of your models. Kubeflow provides built-in support for logging and visualizing these metrics.
-
Model Drift Detection: Implement mechanisms to detect model drift, which occurs when the performance of your model degrades over time due to changes in the data distribution. Kubeflow can help you set up alerts and notifications to detect and address model drift.
-
Continuous Evaluation: Continuously evaluate your models using new data to ensure that they remain accurate and reliable. This involves retraining your models periodically and updating them as needed.
Effective model monitoring helps you maintain the performance and reliability of your machine learning models, ensuring that they continue to deliver accurate results in production.
Deploying and Serving AI Models
Model Serving with KFServing
Deploying and serving machine learning models is a critical step in the AI model lifecycle. KFServing, a component of Kubeflow, simplifies this process by providing a scalable and efficient platform for serving models. Here's how to use KFServing for model serving:
-
Define the Inference Service: Create an inference service definition that specifies the model you want to serve and the resources required for serving it. KFServing supports multiple frameworks, including TensorFlow, PyTorch, and ONNX.
-
Deploy the Inference Service: Use the kubectl command to deploy the inference service to your Kubernetes cluster. KFServing will automatically handle the deployment and scaling of the service.
-
Monitor the Service: Monitor the performance of the inference service using built-in metrics and logging. KFServing provides detailed metrics on request latency, throughput, and resource utilization.
-
Update the Model: When you need to update the model, simply update the inference service definition and redeploy it. KFServing supports rolling updates, ensuring that the new model is deployed seamlessly without downtime.
By using KFServing, you can efficiently deploy and serve your machine learning models, ensuring that they are available for inference in a production environment. For more insights, check out the architecture of Kubeflow for machine learning.
Scaling and Managing Deployments
Scaling and managing model deployments is essential for handling varying workloads and ensuring that your models can serve requests efficiently. Kubeflow provides various features to help you scale and manage your deployments effectively:
-
Automatic Scaling: Configure automatic scaling for your inference services based on request load. This ensures that your services can handle increased traffic without manual intervention.
-
Resource Management: Set resource limits and requests for your inference services to ensure that they have the necessary computational resources to operate efficiently.
-
Load Balancing: Implement load balancing to distribute requests evenly across multiple instances of your inference services. This helps maintain the performance and availability of your models.
Effective scaling and management of model deployments ensure that your machine learning models can handle varying workloads and deliver consistent performance in a production environment.
Ensuring Model Robustness and Reliability
Ensuring the robustness and reliability of your machine learning models is crucial for maintaining their performance and trustworthiness. Here are some key practices to follow:
-
Continuous Testing: Implement continuous testing to validate the performance of your models using new data. This helps identify any potential issues early and ensures that your models remain accurate and reliable.
-
Version Control: Use version control for your models to track changes and maintain a history of different model versions. This allows you to revert to a previous version if needed and ensures reproducibility.
-
Monitoring and Alerts: Set up monitoring and alerts to detect any anomalies in the performance of your models. This helps you address issues promptly and maintain the reliability of your models.
By following these practices, you can ensure that your machine learning models are robust and reliable, delivering accurate results consistently in a production environment.
Best Practices for AI Model Lifecycle Management
Managing the AI model lifecycle effectively requires following best practices that ensure the efficiency, scalability, and reliability of your machine learning workflows. Here are some key best practices to consider:
Pipeline Modularity for Maintainability
Modularity is essential for maintaining complex machine learning workflows. By breaking down your workflows into modular components, you can manage and update each component independently. This enhances the maintainability of your workflows and makes it easier to implement changes and improvements.
-
Design your pipelines with reusable components.
-
Encapsulate each stage of the workflow as a separate module.
-
Use version control to track changes to individual components.
Effective Resource Management
Managing computational resources effectively is crucial for optimizing the performance of your machine learning workflows. Here are some tips for effective resource management:
-
Set resource limits and requests for each component in your workflows.
-
Monitor resource usage to identify and address bottlenecks.
-
Implement automatic scaling to handle varying workloads.
Implementing Security Best Practices
Security is a critical aspect of AI model lifecycle management. Implementing security best practices helps protect your data, models, and infrastructure from potential threats. Here are some key security practices to follow:
-
Configure authentication and authorization to control access to your workflows.
-
Encrypt data at rest and in transit to protect sensitive information.
-
Regularly update and patch your software to address security vulnerabilities.
Implementing Security Best Practices
Security is a critical aspect of AI model lifecycle management. Implementing security best practices helps protect your data, models, and infrastructure from potential threats. Here are some key security practices to follow:
-
Configure authentication and authorization to control access to your workflows.
-
Encrypt data at rest and in transit to protect sensitive information.
-
Regularly update and patch your software to address security vulnerabilities.
Real-world Applications and Success Stories
Kubeflow has been adopted by numerous organizations to streamline their AI model lifecycle management. Here are a few success stories that highlight its impact:
Uber: Optimizing AI Workflows
Uber uses Kubeflow to manage its AI workflows efficiently. By leveraging Kubeflow Pipelines and TFJob, Uber has been able to automate and scale its machine learning processes, reducing the time required to deploy new models. This has enabled Uber to enhance its ride-hailing services with improved ETA predictions and dynamic pricing models.
Spotify: Enhancing User Experiences with ML
Spotify utilizes Kubeflow to enhance user experiences through personalized music recommendations. By using Katib for hyperparameter tuning and KFServing for model deployment, Spotify can continuously optimize its recommendation algorithms. This has resulted in more accurate and relevant music suggestions for users, increasing user engagement and satisfaction.
Other Notable Implementations
Other organizations, such as Google, Microsoft, and Red Hat, have also adopted Kubeflow to streamline their AI model lifecycle management. These companies have reported significant improvements in the efficiency and scalability of their machine learning workflows, enabling them to deliver innovative AI solutions more rapidly.
Conclusion: Transforming AI Workflows with Kubeflow
Kubeflow on Kubernetes offers a powerful and flexible platform for managing the AI model lifecycle. By leveraging its modular components, you can streamline the process of building, training, deploying, and monitoring machine learning models. This ensures that your AI projects are scalable, efficient, and reliable.
-
Adopt Kubeflow to enhance the scalability and portability of your AI workflows.
-
Utilize Kubeflow Pipelines to orchestrate complex machine learning workflows.
-
Automate hyperparameter tuning with Katib to optimize model performance.
-
Deploy and serve models efficiently with KFServing.
-
Implement security best practices to protect your data and models.
Summary of Key Insights
In summary, Kubeflow provides a comprehensive solution for managing the AI model lifecycle on Kubernetes. Its core components, such as Kubeflow Pipelines, Katib, and TFJob, enable you to build, train, and deploy models more efficiently. By following best practices for pipeline modularity, resource management, and security, you can ensure that your machine learning workflows are robust and reliable.
Real-world success stories from companies like Uber and Spotify demonstrate the transformative impact of Kubeflow on AI workflows. As the adoption of Kubeflow continues to grow, it is poised to play a crucial role in the future of AI model lifecycle management.
“Kubeflow simplifies the deployment and management of machine learning workflows on Kubernetes, making it easier for data scientists and ML engineers to build, train, and deploy models at scale.”
Future Trends in AI Model Lifecycle Management
The future of AI model lifecycle management is likely to see further advancements in automation, scalability, and integration. Here are some trends to watch for:
-
Increased Automation: Enhanced automation tools will further streamline the AI model lifecycle, reducing the need for manual intervention and enabling faster deployment of models.
-
Improved Scalability: Advances in Kubernetes and Kubeflow will enable even greater scalability, allowing organizations to handle larger datasets and more complex models.
-
Seamless Integration: Integration with other AI and data tools will become more seamless, providing a unified platform for managing the entire AI workflow.
Frequently Asked Questions (FAQ)
What is the primary function of Kubeflow?
Kubeflow is an open-source platform designed to simplify the deployment and management of machine learning workflows on Kubernetes. It provides a comprehensive set of tools and frameworks for building, training, and deploying AI models at scale.
Why is Kubernetes beneficial for AI model management?
Kubernetes offers robust infrastructure for automating the deployment, scaling, and management of containerized applications. In AI model management, Kubernetes ensures scalability, portability, and efficient resource utilization, making it an ideal platform for managing complex machine learning workflows.
How can I ensure the security of my AI models in Kubeflow?
To ensure the security of your AI models in Kubeflow follow best practices like encrypting your data, keeping your software patched and updated and managing access to your workflows.